In today’s data-driven world, information is everywhere, and the internet serves as a goldmine of valuable data. Whether you are a researcher seeking critical insights, an entrepreneur tracking market trends, or a data enthusiast hungry for knowledge, the vast expanse of the web holds a treasure trove of possibilities. However, the sheer volume of data available on the internet can quickly become overwhelming. Manual data collection from websites can be a time-consuming and laborious process, leaving you searching for a more efficient solution. Fear not, for there is a powerful technique at your disposal – web scraping, the hero that can rescue you from the drudgery of manual data extraction! Web scraping empowers you to automate the process of collecting data from websites, turning hours of work into a matter of moments. In this blog post, we will delve into the world of web scraping, explore its potential applications, and discover various techniques used to gather this vast amount of information in just a matter of seconds. So, buckle up as we embark on a journey to harness the true power of web scraping!
What is Web Scraping
Web scraping is the process of extracting data from websites automatically and converting it into a structured format for further analysis. It involves using software or scripts to access web pages, download their contents, and extract specific information from them. The data retrieved through web scraping can include text, images, URLs, tables, and more.

Why do we need to Web Scrape?
Think of a scenario where you want to find the perfect holiday destination for your upcoming trip. You’re eager to compare hotel prices, check out tourist attractions, and read reviews from fellow travellers. However, the thought of manually visiting each travel website, copying information, and organizing it into a meaningful format sounds daunting and time-consuming. This is where web scraping comes to the rescue.
Imagine having a virtual travel assistant that can swiftly visit various travel websites, scrape hotel prices, tour packages, and user reviews, and present it all in a neat and organized manner. Within minutes, you have a comprehensive overview of different destinations, their offerings, and the experiences of other travelers. With a little help of web scraping, all this could be possible.
Getting Started with Web Scraping
Before delving into web scraping techniques, it’s essential to first determine the type of website you intend to scrape, as there are two main categories: static and dynamic websites. Understanding this distinction will help you choose the appropriate approach and tools for your web scraping endeavor.
Types of Websites
There are two main types of websites:
1. Static:
Static websites are websites that do not change unless they are manually updated. They are typically made up of HTML, CSS, and JavaScript files that are stored on a web server. When a user visits a static website, their browser downloads the files and renders them as a web page.
Here are some examples of static websites:
- Portfolio websites that showcase a person’s work
- Company websites that provide information about a business
- Blogs that are updated infrequently
2. Dynamic:
Dynamic websites are websites that can change depending on the user’s input or the current state of the website. They are typically made using server-side programming languages such as PHP, Python, or Java. When a user visits a dynamic website, their request is sent to the web server, which then executes the appropriate code to generate the web page.
Here are some examples of dynamic websites:
- E-commerce websites that allow users to buy and sell products
- Social media websites that allow users to interact with each other
- News websites that update their content frequently
The best type of website for you will depend on your specific needs. If you need a website that is simple and easy to maintain, then a static website may be a good choice. However, if you need a website that is more interactive or dynamic, then a dynamic website may be a better choice.
Various Approaches to scrape data from websites.
Let’s explore the numerous approaches available to extract data from diverse websites, examining each method in detail.
- Use of Web Scraping Libraries for Data Extraction
Web scraping libraries are tools that allow developers to extract data from websites programmatically. These libraries provide convenient methods and utilities to navigate web pages, retrieve data, and parse the content in a structured format. Some popular web scraping libraries include.
Web scraping libraries are tools that allow developers to extract data from websites programmatically. These libraries provide convenient methods and utilities to navigate web pages, retrieve data, and parse the content in a structured format. Some popular web scraping libraries include
- BeautifulSoup (Python):
BeautifulSoup is a Python library used for web scraping tasks. It allows you to extract information from HTML and XML documents by providing a simple interface for parsing and navigating the document’s elements. BeautifulSoup creates a parse tree that can be traversed to locate specific data, such as text, links, images, and more.
- Selenium (Python):
Selenium is not strictly a web scraping library but a web testing framework. However, it is frequently used for web scraping tasks that require interactions with JavaScript-rendered content or websites that have a heavy reliance on JavaScript. Selenium simulates a browser, allowing you to interact with the page, fill out forms, and click buttons.
- Requests (Python):
While Requests is not primarily a web scraping library, it is a widely-used Python HTTP library that allows you to make HTTP requests to websites. It is often used in conjunction with BeautifulSoup for simple scraping tasks. Requests provide a straightforward way to download HTML content from a website, which can then be parsed using BeautifulSoup or other parsing libraries.
- Scrapy (Python):
Scrapy is a powerful and flexible Python framework designed specifically for web scraping. It offers a comprehensive set of tools for crawling and extracting data from websites. Scrapy handles request scheduling, managing cookies, handling exceptions, and parsing data with ease. It is suitable for more complex scraping tasks and is often used to build full-fledged web crawlers.
- Playwright:
Playwright is a new web scraping framework from Microsoft. It is a powerful tool that can be used to scrape websites that use JavaScript. Playwright was developed especially to meet the requirements of end-to-end testing. All recent rendering engines, including Chromium, WebKit, and Firefox, are supported by Playwright.
Here is a table that summarizes the features of these libraries:
| Library | Features | Pros | Cons |
| Beautiful Soup | Easy to learn and use | Parses HTML and XML documents | Not as powerful as other libraries |
| Requests | Efficient and reliable | Makes HTTP requests to websites | Not as easy to use as Beautiful Soup |
| Scrapy | Powerful and versatile | Can be used for complex web scraping projects | Can be difficult to learn |
| Selenium | Can be used to scrape websites that require user interaction | Powerful and versatile | Can be slow and resource-intensive |
| Playwright | New and powerful | Can scrape websites that use JavaScript | Not as well-known as other libraries |
Data Extraction Using Web Scraping Tools
Popular web scraping tools encompass a variety of software applications and services designed to facilitate data extraction from websites. These tools cater to different needs, from simple data extraction with no coding required to more advanced custom scraping projects. Here are some popular web scraping tools:
- Octoparse:
Octoparse is a user-friendly and powerful desktop-based web scraping tool that enables users to extract data from websites without any coding knowledge. It offers a visual point-and-click interface, making it easy to navigate web pages, select data elements, and set up scraping tasks. Octoparse supports various types of data extraction, including text, images, tables, and more.
- ParseHub:
ParseHub is a web scraping tool that provides both free and premium plans. It allows users to extract data from dynamic and static websites with ease. The tool is highly customizable, making it suitable for complex scraping projects. ParseHub offers pre-built templates for some popular websites, which can be a great starting point for beginners.
- Web Scraper (Chrome Extension):
Web Scraper is a browser extension available for Google Chrome that enables users to scrape data from websites directly within the browser. It offers a point-and-click interface for data selection and supports pagination and infinite scrolling, making it useful for scraping multiple pages of data.
- Scrapy:
Scrapy is an open-source Python framework designed for web scraping and crawling tasks. It is more suitable for developers and programmers who have some coding experience. Scrapy provides a robust set of tools for handling HTTP requests, navigating websites, and parsing data.
- Apify:
Apify is a cloud-based web scraping and automation platform that allows users to run scraping tasks at scale without managing infrastructure. It supports headless browsers (such as Chrome and Firefox) and simple HTML scraping with Cheerio.
- Import.io:
Import.io is a cloud-based web scraping tool that is more expensive than other tools on this list. However, it is very powerful and can be used to scrape data from a variety of websites.
Here is a table that summarizes the features of these tools:
| Tool | Features | Pros | Cons |
| Octoparse | Cloud-based, easy to use, no coding required | Easy to get started, good for beginners | Not as powerful as other tools, limited features |
| ParseHub | Desktop-based, powerful, JavaScript and AJAX support | Powerful, good for complex websites | More difficult to learn than Octoparse, not as user-friendly |
| Web Scraper | Free and open-source, written in Python | Free, good for developers | Not as user-friendly as other tools, less powerful |
| Scrapy | Powerful, versatile, written in Python | Powerful, versatile, good for complex websites | More difficult to learn than other tools |
| Import.io | Cloud-based, powerful, JavaScript and AJAX support | Very powerful, good for complex websites | Expensive, not as user-friendly as other tools |
| Apify | Cloud-based, Large community, Technical knowledge required | Easy to use, scalable, reliable, versatile, easy to find help and support | Can be expensive for some users, can be overwhelming and difficult to learn |
NOTE:
When it comes to automated scraping, legality is a significant concern. Some websites explicitly prohibit scraping in their terms of service. Others may allow scraping for personal use but not for commercial purposes. Before performing any scraping, it is essential to review the website’s terms of service and, if necessary, seek permission from the website owner to avoid potential legal issues.
The Use of APIs for Data Extraction
APIs (Application Programming Interfaces) plays a vital role in data extraction by providing a structured and standardized way for different software applications to communicate and exchange information. In the context of data extraction, APIs act as bridges between data sources, such as websites or web services
, and the applications that need to retrieve specific data from them.
When extracting data using APIs, developers can send requests to the API server, specifying the type of data they want and any parameters needed for the query. The API server then processes the request and returns the requested data in a structured format, such as JSON or XML. This data can include text, images, statistics, or any other relevant information available through the API.
Using APIs for data extraction offers several advantages. Firstly, APIs provide a consistent and predictable way to access data, ensuring that the information retrieved is always in a standardized format. Secondly, APIs often come with built-in security mechanisms, such as API keys or authentication tokens, which control access to data and prevent unauthorized usage. Thirdly, APIs can be more efficient than traditional web scraping methods, as they allow direct access to the specific data required without having to parse and navigate through entire web pages.
Furthermore, APIs are often maintained and updated by the service providers, ensuring that the data accessed through them is reliable, up-to-date, and compliant with the latest standards. Many websites and platforms offer APIs as part of their services, making it easier for developers to access and integrate data into their applications.
NOTE:
Using APIs for data extraction is generally more acceptable from a legal standpoint compared to web scraping. When you use an API, you are directly cooperating with the data provider and adhering to their terms of service. API providers set rules and restrictions on how their data can be accessed and used, and by using their API, you agree to abide by those rules.
However, it is essential to review the API provider’s terms of service and usage policies to ensure you are in compliance. Some APIs may have usage limits, require attribution, or charge fees for access beyond a certain threshold.
Applications of Web Scraping
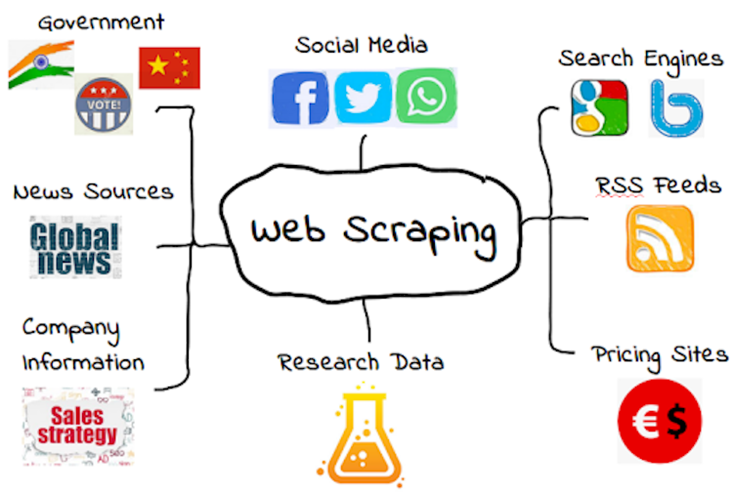
There are wide range of applications to web scraping. Here are some common applications of web scraping:
- Market research: Web scraping enables businesses to gather data on competitors, pricing, product listings, and customer reviews, helping them make informed decisions and stay competitive.
- Business intelligence: By scraping data from various sources, businesses can gather insights on market trends, customer behaviour, and industry developments to improve their strategies.
- Lead generation: Web scraping can be used to collect contact information, email addresses, and other relevant data from websites to create potential customer leads for marketing and sales purposes.
- Content aggregation: News websites, blogs, and content platforms often use web scraping to collect and curate relevant content from different sources automatically.
- Financial data analysis: Finance professionals use web scraping to gather financial data, stock market information, economic indicators, and other data to inform their investment decisions.
- Sentiment analysis: Social media platforms can be scraped to analyze user sentiments and opinions about products, services, or events.
- Academic research: Researchers often use web scraping to collect data for studies, surveys, and analysis across various fields.
- Real estate and property data: Web scraping helps gather property listings, rental prices, and other real estate-related information for analysis and decision-making.
- Job market analysis: Web scraping job portals can provide insights into job trends, demand for specific skills, and salary information.
- Weather data collection: Weather forecasting websites can be scraped to collect real-time weather data for analysis and prediction.
- Government data analysis: Government websites contain vast amounts of public data that can be scraped for research, transparency, and policy-making purposes.
- Travel planning: Web scraping can gather information on flight prices, hotel rates, and tourist attractions to help travellers plan their trips more efficiently.
- Automating tasks: Web scraping can be used to automate tasks that would otherwise be time-consuming or tedious. For example, web scraping can be used to automatically collect product reviews, generate reports, or update databases.
Web Scraping on Python
Let’s explore the fundamentals of web scraping using Python, examining the basic techniques for extracting data from websites. By delving into the basics, you’ll gain a better understanding of the different approaches to web scraping. Let’s get started!
.Let’s get started!
-Loading Necessary Packages
-Scraping for Static Website
-Scraping for Dynamic Website
-Advanced Scraping
1. Understanding Web Scraping
Web scraping involves accessing websites, downloading HTML content, and extracting relevant data. It’s essential to know the basics of HTML, CSS, and HTTP requests to get started.
2. Understanding HTML and CSS
HTML (Hypertext Markup Language) is used to structure the content of a webpage, while CSS (Cascading Style Sheets) is used to style and layout the HTML elements. Understanding these two is crucial for web scraping as it helps you locate and extract the data you need.
HTML (Hypertext Markup Language): HTML is the backbone of web pages and is used to structure the content of a website. It consists of various elements, each represented by tags, which define the structure and layout of the page. Web scrapers use HTML tags to identify and extract specific data from a webpage. For example, a data table on a website may be enclosed within “table” tags, and each row of the table may be represented by “tr” tags.
CSS (Cascading Style Sheets):
CSS is a style sheet language used to control the presentation and layout of web pages. It defines how HTML elements should be displayed on the screen, specifying attributes such as font size, colour, and positioning. While web scraping focuses on data extraction, understanding CSS selectors can be valuable for targeting specific elements within the HTML document efficiently.
3. Installing Required Libraries
Assuming you have chosen BeautifulSoup to web scrape. Firstly, you need to install it, use the following command on your terminal or command prompt.
pip install beautifulsoup4This command will download and install the BeautifulSoup library on your system. BeautifulSoup is a popular Python library for web scraping, and it simplifies the process of parsing HTML and XML documents, making it easier to extract data from websites. Once installed, you can use the BeautifulSoup library in your Python scripts to navigate and extract information from web pages effortlessly.
Depending on the usage and the website, you can choose to install other necessary packages like
pip install requests
pip install seleniumLet’s explore different situations where you can effectively utilize these in web scraping. Understanding its usage in various scenarios will provide valuable insights into how these libraries can be applied to extract data from websites efficiently and adapt to different web scraping needs.
4. Loading Necessary Packages
We will introduce and explore several packages that we will use one by one for web scraping. Additionally, feel free to utilize any other packages of your choice, as Python offers a wide range of tools that can enhance and streamline the web scraping process.
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
Our focus will be on demonstrating the versatility of these packages and how they can be combined to extract valuable data from websites efficiently. So, let’s get ready to explore the world of web scraping with Python and unleash the power of various packages to make our scraping endeavours more effective and enjoyable.
5. Scraping for Static Website
Now that we have understood what are static websites, the simplest way to scrape them is using the ‘requests’ library. Since static websites present all the data directly in the HTML code when the page loads, this makes it easier to extract information using libraries like BeautifulSoup.
Let us consider an example to scrape a static website i.e.,
Input:
import requests
from bs4 import BeautifulSoup
url = 'https://en.wikipedia.org/wiki/Web_scraping'
response = requests.get(url)
print(response.status_code)
print(response.content)
Output:
200
b'<!DOCTYPE html>\n<html class="client-nojs vector-feature-language-in-header-enabled vector-feature-language-in-main-page-header-disabled vector-feature-sticky-header-disabled vector-feature-page-tools-pinned-disabled vector-feature-toc-pinned-enabled vector-feature-main-menu-pinned-disabled vector-feature-limited-width-enabled vector-feature-limited-width-content-enabled vector-feature-zebra-design-disabled" lang="en" dir="ltr">\n<head>\n<meta charset="UTF-8">\n<title>Web scraping - Wikipedia</title>\n<script>document.documentElement.className="client-js vector-feature-language-in-header-enabled vector-feature-language-in-main-page-header-disabled vector-feature-sticky-header-disabled vector-feature-page-tools-pinned-disabled vector-feature-toc-pinned-enabled vector-feature-main-menu-pinned-disabled vector-feature-limited-width-enabled vector-feature-limited-width-content-enabled vector-feature-zebra-design-disabled";(function(){var cookie=document.cookie.match(/(?:^|; )enwikimwclientprefs=([^;]+)/);if(cookie){var featureName=cookie[1];document.documentElement.className=document.documentElement.className.replace(featureName+\'-enabled\',featureName+\'-disabled\');}}());RLCONF={"wgBreakFrames":false,"wgSeparatorTransformTable":["",""],"wgDigitTransformTable":["",""],"wgDefaultDateFormat":"dmy","wgMonthNames"
In this code snippet, we are performing web scraping on the Wikipedia page about “Web scraping.” Let’s break down the steps:
- url = ‘https://en.wikipedia.org/wiki/Web_scraping’: We define the URL of the webpage we want to scrape, which is the Wikipedia page on Web scraping.
- response = requests.get(url): We use the requests library to make an HTTP GET request to the specified URL. This request is used to fetch the content of the webpage.
- print(response.status_code): After making the request, we print the status code of the response. The status code is a three-digit number that indicates the result of the HTTP request. A status code of 200 means the request was successful, while a status code starting with 4 or 5 indicates an error (e.g., 404 for “Not Found” or 500 for “Internal Server Error”). This is an optional step, mainly used for error handling.
- print(response.content): We print the content of the response, which contains the HTML content of the webpage. This content is a raw byte-string representation of the HTML page.
Input:
soup = BeautifulSoup(response.content, 'html.parser')
print(soup)
Output:
<!DOCTYPE html>
<html class="client-nojs vector-feature-language-in-header-enabled vector-feature-language-in-main-page-header-disabled vector-feature-sticky-header-disabled vector-feature-page-tools-pinned-disabled vector-feature-toc-pinned-enabled vector-feature-main-menu-pinned-disabled vector-feature-limited-width-enabled vector-feature-limited-width-content-enabled vector-feature-zebra-design-disabled" dir="ltr" lang="en">
<head>
<meta charset="utf-8"/>
<title>Web scraping - Wikipedia</title>
<script>document.documentElement.className="client-js vector-feature-language-in-header-enabled vector-feature-language-in-main-page-header-disabled vector-feature-sticky-header-disabled vector-feature-page-tools-pinned-disabled vector-feature-toc-pinned-enabled vector-feature-main-menu-pinned-disabled vector-feature-limited-width-enabled vector-feature-limited-width-content-enabled vector-feature-zebra-design-disabled";(function(){var cookie=document.cookie.match(/(?:^|; )enwikimwclientprefs=([^;]+)/);if(cookie){var featureName=cookie[1];document.documentElement.className=document.documentElement.className.replace(featureName+'-enabled',featureName+'-disabled');}}());RLCONF={"wgBreakFrames":false,"wgSeparatorTransformTable":["",""],"wgDigitTransformTable":["",""],"wgDefaultDateFormat":"dmy","wgMonthNames":["","January","February","March","April","May","June","July","August","September","October","November","December"],"wgRequestId":"226f86bd-a2e6-40c7-920a-8d9d2de6b0db","wgCSPNonce":false,
"wgCanonicalNamespace":"","wgCanonicalSpecialPageName":false,"wgNamespaceNumber":0,"wgPageName":"Web_scraping","wgTitle":"Web scraping","wgCurRevisionId":1161609714,"wgRevisionId":1161609714,"wgArticleId":2696619,"wgIsArticle":true,"wgIsRedirect":false,"wgAction":"view","wgUserName":null,"wgUserGroups":["*"],"wgCategories":["CS1 Danish-language sources (da)","CS1 French-language sources (fr)","Articles with short description","Short description matches Wikidata","Articles needing additional references from April 2023","All articles needing additional references","Articles needing additional references from October 2018","Articles with limited geographic scope from October 2015","United States-centric","All articles with unsourced statements","Articles with unsourced statements from April 2023","Web scraping"],"wgPageViewLanguage":"en","wgPageContentLanguage":"en","wgPageContentModel":"wikitext","wgRelevantPageName":"Web_scraping","wgRelevantArticleId":2696619,"wgIsProbablyEditable":
true,"wgRelevantPageIsProbablyEditable":true,"wgRestrictionEdit":[],"wgRestrictionMove":[],"wgFlaggedRevsParams":{"tags":{"status":{"levels":1}}},"wgVisualEditor":{"pageLanguageCode":"en","pageLanguageDir":"ltr","pageVariantFallbacks":"en"},"wgMFDisplayWikibaseDescriptions":{"search":true,"watchlist":true,"tagline":false,"nearby":true},"wgWMESchemaEditAttemptStepOversample":false,"wgWMEPageLength":30000,"wgNoticeProject":"wikipedia","wgMediaViewerOnClick":true,"wgMediaViewerEnabledByDefault":true,"wgPopupsFlags":10,"wgULSCurrentAutonym":"English","wgEditSubmitButtonLabelPublish":true,"wgCentralAuthMobileDomain":false,"wgULSPosition":"interlanguage","wgULSisCompactLinksEnabled":true,"wgULSisLanguageSelectorEmpty":false,"wgWikibaseItemId":"Q665452","
Let us break down the following code snippet
- soup = BeautifulSoup(response.content, ‘html.parser’): We create a BeautifulSoup object named soup by passing two arguments: response.content and ‘html.parser’. The first argument, response.content, contains the raw HTML content of the webpage obtained from the previous requests.get() call. The second argument, ‘html.parser’, is the name of the parser that BeautifulSoup should use to parse the HTML content. In this case, we are using the built-in HTML parser provided by BeautifulSoup, which is called html.parser.
- print(soup): We are just displaying the content further
Let us assume we want to find the title of this page, we need to seach on the HTML page the class that holds the title element.
Input:
title_element = soup.find('span', class_='mw-page-title-main')
print(title_element)
print(title_element.text.strip())
Output:
<span class="mw-page-title-main">Web scraping</span>
Web scraping
7. title_element = soup.find(‘span’, class_=’mw-page-title-main’): We use the soup.find() method to search for an HTML element with the <span> tag and the CSS class mw-page-title-main. The find() method returns the first occurrence of the element that matches the specified tag and class criteria. If no matching element is found, the find() method returns None. The result of this search is assigned to the variable title_element. Depending on the situation use find() or find_all()
8. print(title_element): We print the value of title_element. This will display the entire HTML element (i.e., the <span> element with the class mw-page-title-main).
9. print(title_element.text.strip()): We access the text content of the title_element using the .text attribute. The .text attribute returns the text content of the HTML element, excluding any HTML tags. The strip() method is then applied to remove any leading or trailing whitespaces from the extracted text content. Finally, we print the result, which is the main title of the web page without any unwanted whitespace.
This is how you can scrape a static website, lets now look into how we could scrape dynamic websites.
6. Scraping for Dynamic Website
We will scrape data from a dynamic website, where content is loaded using JavaScript. For this purpose, we will use Selenium. There are times when the scraping requires you to interact with the websites dynamically, hence we use webdrivers to achieve this.
options = Options()
options.add_argument('--headless')
browser = webdriver.Chrome(options=options)
browser.get(url)
page_source = browser.page_source
browser.quit()
soup = BeautifulSoup(page_source, 'html.parser')
In this code snippet, we are using Selenium to scrape data from a dynamic website, where content is loaded using JavaScript. Here’s an explanation of the steps:
- options = Options(): We create an instance of the Options class from Selenium. This allows us to set various options and preferences for the web browser we are using with Selenium.
- options.add_argument(‘–headless’): We set the option –headless, which runs the browser in headless mode. Headless mode means the browser runs without displaying a graphical user interface (GUI), providing a more efficient and faster way to scrape data without the need for a visible browser window.
- browser = webdriver.Chrome(options=options): We create an instance of the Chrome WebDriver using the webdriver.Chrome() method and pass the options object we created earlier. This sets up the Chrome browser in headless mode with the specified options.
- browser.get(url): We use the get() method to navigate to the URL of the dynamic website. The browser will load the webpage and execute any JavaScript code, which may load additional content dynamically.
- browser.quit(): Once the details are extracted, we can close the browser, since no more interactions with the website is necessary.
- page_source = browser.page_source: We retrieve the page source of the loaded webpage using the page_source attribute. The page source contains the entire HTML content of the webpage after JavaScript execution, including any dynamically loaded content.
- We later use BeautifulSoup to parse the details, same as the previous procedure
7. Advanced Scraping
This section will cover more advanced techniques, such as handling pagination
options = Options()
options.add_argument('--headless')
browser = webdriver.Chrome(options=options)
browser.get(url)
button = WebDriverWait(browser, 10).until(EC.visibility_of_element_located((By.XPATH, “XPath_Class”)))
button.click()
page_source = browser.page_source
browser.quit()
soup = BeautifulSoup(page_source, 'html.parser')
In web scraping, pagination refers to the practice of dealing with websites that display data across multiple pages. Instead of showing all the information on a single page, the website splits the data into several pages to improve readability and load times. Handling pagination is essential when you want to scrape data from all the pages of a website.
All steps are similar to the previous codes, but here we have added a button,
- button: Here, we create an instance of WebDriverWait, which allows us to set a maximum waiting time of 10 seconds (10 in the code) for an element to become visible on the page. We pass two arguments to WebDriverWait: the browser object, which represents the current browser instance, and the expected condition (EC) that we want to wait for. In this case, we are waiting for the element located by the XPath “XPath_Class” to become visible on the page.
- button.click(): Once the button element is visible (and the WebDriverWait stops waiting), we use the click() method on the button object to simulate a click on the button. This will trigger any associated JavaScript actions on the webpage, such as loading additional content or navigating to another page.
Hence with the various use cases and techniques covered in web scraping, you gain the ability to accomplish remarkable tasks. However, it is crucial to remember that the success of your web scraping endeavours depends on understanding when to employ the appropriate approach for different scenarios. In this blog I have covered only the necessary aspects. Being mindful of these aspects will ensure that you choose the right tools and methods, making your web scraping process more effective, efficient, and responsible.
Conclusion
In conclusion, Web Scraping is a powerful and versatile technology that has revolutionized the way we gather and utilize data from the internet. By automating the process of extracting information from websites, Web Scraping enables businesses, researchers, and individuals to access vast amounts of valuable data quickly and efficiently. From market research and competitive analysis to academic research and real estate data collection, Web Scraping plays a pivotal role in a wide range of fields. However, it is essential to use Web Scraping responsibly and ethically, respecting website terms of service and privacy regulations. With the continued advancement of technology, Web Scraping will undoubtedly continue to be a vital tool for unlocking insights and driving innovation in the digital age.
References
1. https://www.imperva.com/learn/application-security/web-scraping
2. https://www.geeksforgeeks.org/what-is-web-scraping-and-how-to-use-it/