Transformer models have achieved a significant milestone in the field of NLP. Not only in the field of NLP, but also in Computer Vision, we can see Transformer models outperforming all the so-called state-of-the-art models. Transformers have been proven to improve long-term dependencies and can be used to leverage the technique called Transfer learning, which is very useful when we have less amount of data.
If you like to read more about Transformers, please refer my previous blog post.
There are so many models available today, which are inspired by transformer architecture. In this blog, we will be discussing some popular Transformer based models. We will see the architecture, components, working, and the training process of each of these models.
GPT
GPT stands for Generative Pre-trained Transformer. If you remember the architecture of Transformers, you might be knowing that the Transformers are made of Encoder stack and Decoder stack. GPT is essentially the decoder stack in the Transformer. The decoder stack in Transformers was responsible for predicting each word of the output sequence. Given the previous words, the decoder is trained to predict the current word in the sequence. The previous stage input along with the current predicted word form the input for predicting the next word. This type of model is called the Autoregressive model. So we can understand the GPT model as a next word prediction model, which can be useful in sentence completion, natural language generation and many more.
Architecture
The architecture of a GPT model will look like the below diagram.
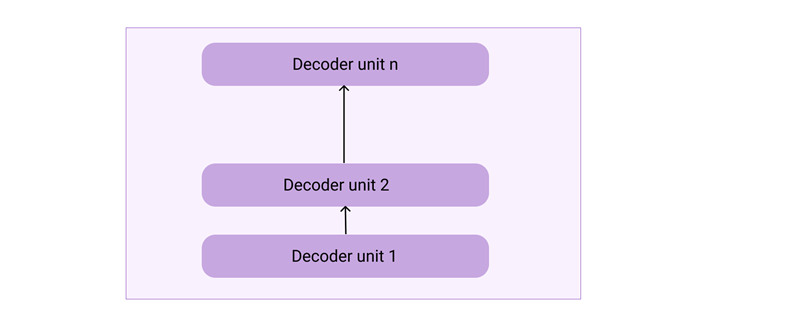
Based on the number of decoder stacks, there are different variations of GPT.
| GPT model | Number of decoder units |
| GPT2 Small | 12 |
| GPT2 Medium | 24 |
| GPT2 Large | 36 |
| GPT2 Extra Large | 48 |
The main purpose of GPT is to generate a sequence, token by token. The input words are passed through an embedding layer that will convert the tokens into embeddings or vectors. These vectors are further encoded using positional encoding. Positional encoding is a way to capture the ordering of words in a sequence and was introduced by the Transformer architecture itself. These vectors are then passed through the first layer in the decoder stack. The output from one decoder stack is passed as the input to the next unit until the last stage. The output from the last decoder stack will be a probability distribution, which indicates the probability of each word in the vocabulary to be the next word in the sequence. The word with the highest probability will be considered as the next word. At each timestamp, the model will use all the previous words to generate the next word. This process will continue until the end of the sequence is reached.
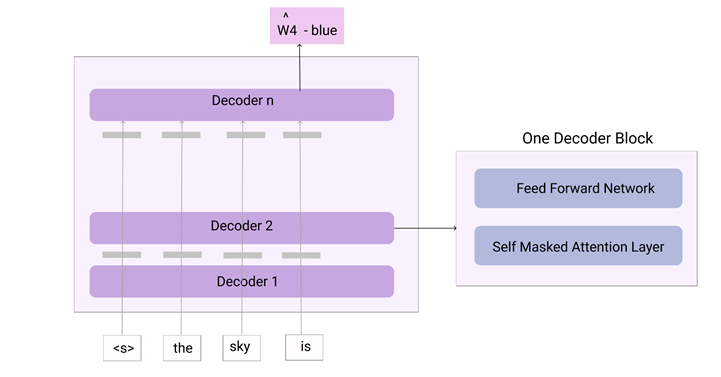
The GPT model was trained on next word prediction using a concept called Masked Self Attention. Masked Self-attention is a method where we mask the present token and the future tokens while predicting the current word. So, while predicting the nth word, we will consider all the previous words, up to the timestamp n-1, and mask all the future words. In this way, the model will predict any word by learning from its past context.
Training
- GPT1 model was trained using the Book Corpus data
- GPT 2 model was trained using WebText data, which was around 40 GB. This text data was crawled from the internet by the researchers and it contained around 8 million documents
- GPT 3 was trained on a mixed corpora. There was a total of five datasets including Common crawl, WebText2, Books1, Books2, and Wikipedia
BERT
BERT stands for Bidirectional Encoder Representations from Transformers.
A transformer model consists of two parts – Encoder Stack(multiple encoder units) and Decoder Stack (multiple decoder units). We have already seen that the GPT model is nothing but the decoder stack of the Transformer. The decoder stack was mainly used to predict the future words in a sentence, while the encoder stack was used to obtain a meaningful encoded representation of the sentence, so that the decoder unit can understand it better. Is there any way we can leverage the Encoder stack as well? The answer is Yes. That is what the BERT model does. BERT is a language model that can generate embeddings by considering the semantic meaning as well as the context of the word.
BERT architecture
As mentioned earlier, BERT is nothing but the encoder stack of the Transformer
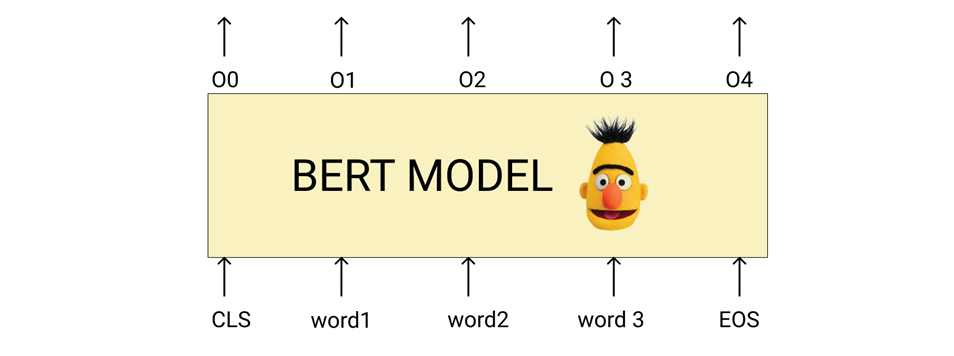
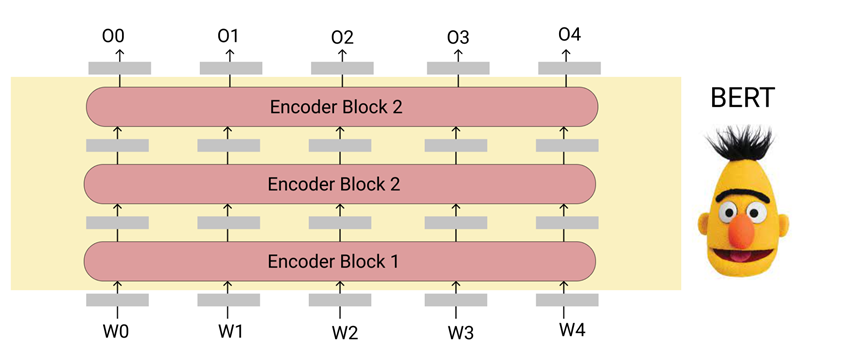
The input to the BERT model will be the words which are encoded (either one-hot encoded or any other encoded forms) and the output from the BERT model will be embeddings of fixed dimensions. In the above figure, O0 is the embeddings corresponding to the first word, O2 will be the second word embeddings and so on. These embeddings can then be used for any downstream task like sentence classification, NER, similarity checking, and so on. The inside of a BERT model will look like this.
Training
Training of the BERT model is done in two steps
- Masked word Prediction
- Next sentence Prediction
Masked word prediction is done by randomly masking some tokens or words in each of the input sentences. The model is trained to predict the masked word. The best thing about this step is that it does not require any labelled data and is completely self-supervised. All we need for training is some text data, and the masked language model will be trained on that, optimizing its weights. At the end of the training the model will be able to understand the language on which it is trained on, and the trained model can be used on various downstream tasks.
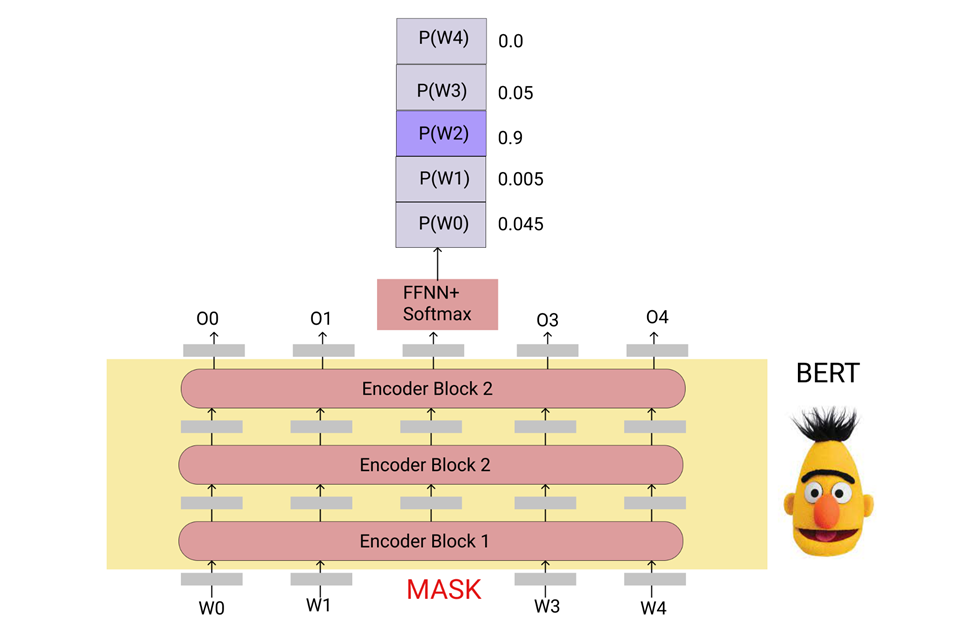
Next Sentence Prediction is used to understand if there is any relation between two sentences. The model is trained to predict if a particular sentence follows another sentence or not. For this task, we will give two sentences, separated by a [SEP] token. Now, the first output from the model is given to a classifier model to predict the probability of “Does the second sentence follow the first sentence?”.
The first input token is always a special classification [CLS] token. So, the final state corresponding to this token is used as the aggregate sequence representation for classification tasks and used for the Next Sentence Prediction where it is fed into a FFNN + SoftMax layer that predicts probabilities for the labels “is Next” or “Not Next”.
BERT is one of the state-of-the-art language models that can be used for various downstream NLP tasks. Since the model is trained on very generic data, this model might not be a very good choice for domain specific tasks. There are various models that are inspired by BERT and are trained for domain specific data. Medical domain is one area where the BERT model is widely used. There are various BERT-based models pretrained on medical data and are used widely in various downstream tasks like NER, Relation extraction etc. Research has also led to the discovery of more robust, fast and lighter versions of BERT.
BIOBERT
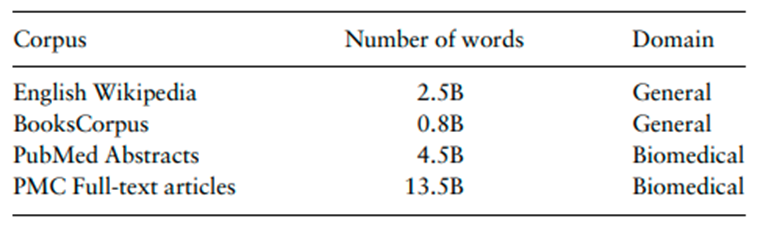
Biobert is the first domain specific model, pre-trained for the medical domain. The model is trained on large scale medical data using PubMed Abstracts and PubMed central full text articles. For training the BioBert model, researchers used the general domain BERT model as the base model, with its optimized weights, and then this model is again fine tuned on the medical data. This type of training is called mixed domain approach. Since the model is already initialized with the optimum general domain weights, the cost for pretraining was less. The corpus used for training the BioBert model is shown below.
The model achieved very good results in the downstream tasks like NER, RE and QA on medical data.
SciBert
Sci-Bert is another domain specific model pre-trained to perform scientific tasks in NLP. Similar to BioBert, this model also leverages the unsupervised training strategy of Transformer models to address the shortage of high quality labelled data. This model is trained on 1.14 Million scientific papers from Semantic Scholar. This data is a mixed domain data with 18% of the papers from the Computer science domain and 82% from the biomedical domain. The corpus contained around 3 Billion words similar to the BERT model. The model was evaluated in downstream tasks like NER, PICO extraction, sentence classification, relation classification, dependency parsing, etc.
PubMed BERT
PubMed BERT was another domain specific BERT based model, trained on biomedical data. This model was developed by Microsoft research during the year 2020. Unlike the above two models that follow a mixed domain training, PubMed model is trained from scratch on the biomedical data. This paper says that training using out-domain text (Wikipedia and book corpus in this case) is a kind of transfer learning, where the source data is the general text corpus and the target domain is medical. Transfer learning is required and is used when the target data source is less and when the source and target data almost matches. In this case the target corpus is very large and it is very different from the source data. The paper proves that biomedical pretraning does not require any mixed domain training approach and it can be done from scratch itself.
Data used for training is PubMed abstracts which contain around 3 Billion words. There is also another version of the PubMed model which is trained using full articles on PubMed central, with a training corpus of around 16.8 Billion words.
ClinicalBert
This is another BERT based model, pre-trained for clinical data – generic clinical text and discharge summaries. Two models were trained on the clinical data
- Clinical BERT – Using the BERT model trained on the general domain as the base model
- Clinical BioBERT – Using the BioBert model as the base model
DistilBERT
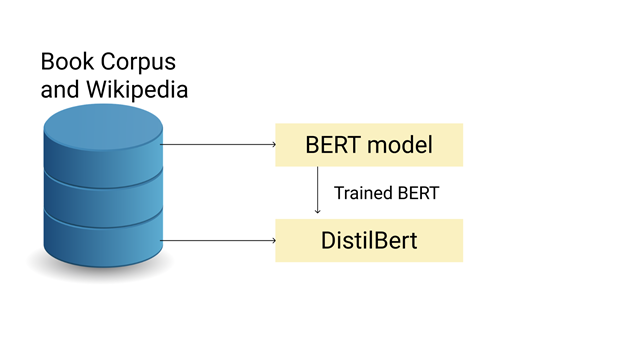
DistilBert is a distilled version of the BERT model. This is a smaller, faster and cheaper version of the BERT model, having 40% fewer parameters than the Bert base model. The architecture is almost similar to the Bert model, but the number of layers are reduced by a factor of 2. DistillBert is trained on large batches of data with dynamic masking and removing the next sentence prediction task. The performance of this model was comparable to other benchmark models, and the model was able to retain more than 95% performance of the BERT base model with fewer parameters.
RoBerta
Roberta follows a Robustly optimized Bert pre-training approach. The paper introduces some design optimization and trains the model further over additional data. The model architecture is the same as that of the Bert model with some changes.
- Removed the next sentence prediction task
- Trained with additional data from CC news, open web text and stories
- Bigger training batch sizes, bigger learning rates and training on longer sequences
- Dynamically changing the masking pattern
XLNET
BERT is an autoencoder language model that will consider both past and future words in constructing the present word. BERT is used to reconstruct the original data, from data which is corrupted using the “masked” tokens. There is however one drawback for this approach. This type of training assumes that the masked tokens are independent of each other and neglect to capture the relation between them if any.
XLNET is an autoregressive language model. Generally an autoregressive(AR) model can consider either the past words or future words in predicting the next word, but it cannot consider both like the BERT model. An example for AR regressive model is GPT which as explained above learns only in one direction during the training process. But XLNET will modify this concept by letting the AR model learn from bidirectional context. XLNET introduces Permutation Language Modeling during the pretraining phase to achieve this. Here, in order to predict the word at nth position, we will put that word in all positions, and use different combinations of the rest of the words before the target word. This will be more clear from the below example.
Let’s say, our sequence length is 4 and we want to predict the third word.
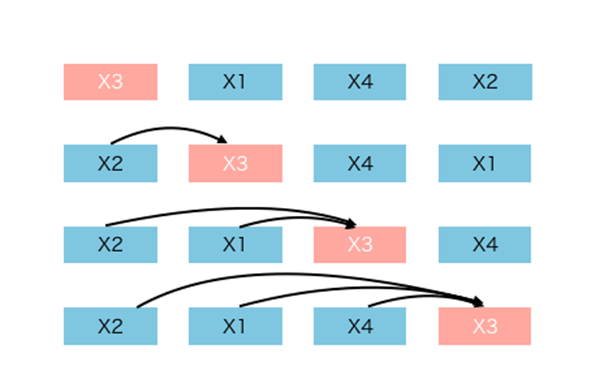
Here, for predicting X3, we put that word in all different positions. Then we consider the combinations of all the remaining words, and hence this achieves a bidirectional learning. After training, a particular target word will be learning its context from both sides.