SQL stands for Structured Query Language and is a very critical tool for Data Scientist. A query language is a type of programming language which is designed to facilitate the information retrieval from the databases as per requirement. We can also call SQL a language for databases in a layman term.
Most of the companies store their data in some or other forms of databases be it My SQL, MS SQL Server or PostgreSQL, but the underlying concept behind querying remains more or less same and if you are aware of the basics behind SQL, you will be able to work with any of them.
Even if you are planning to do your analysis with Python, R, or any other language, chances are you would be required to get the data you need from the company’s database, and having a good foundation of SQL would just ease the process of analysis.
RDBMS
RDBMS stands for Relation Database Management System that stores related information across multiple tables in a structured manner and one can retrieve information from more than one table at the same time based on some common column present across multiple tables of interest.
Below is the sample table that is found in RDBMS databases:
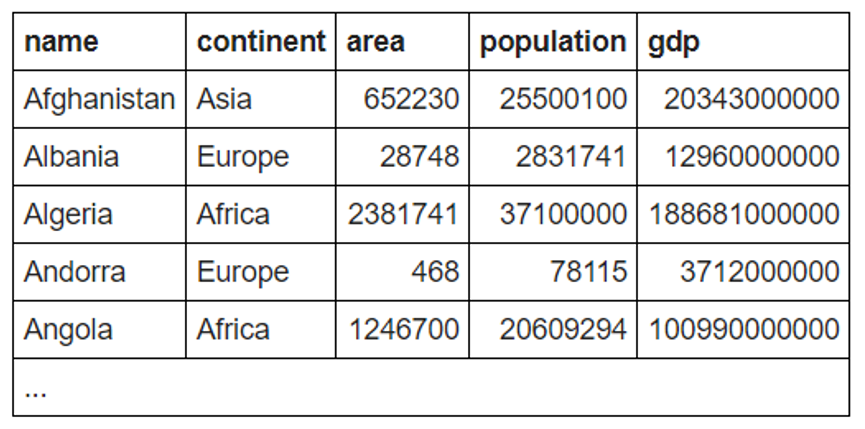
Each row represents the information related to a country and each column represent different attribute of that country, like which continent it belongs to, what is the area, population and GDP of the country.
Now, after the basic understanding of the tables, it’s time to learn how to retrieve a specific information from the database using SQL.
SELECT, COUNT & DISTINCT COUNT, LIMIT
To get an overall idea of the data present in a table we can have a look on some of the entries present and for that we can use LIMIT with SELECT.
SELECT fetches the data whereas LIMIT makes sure we are able to see a particular number of rows only.
We will be using the above table for illustration purpose and we can assume the table name to be world.
select * from world limit 5;
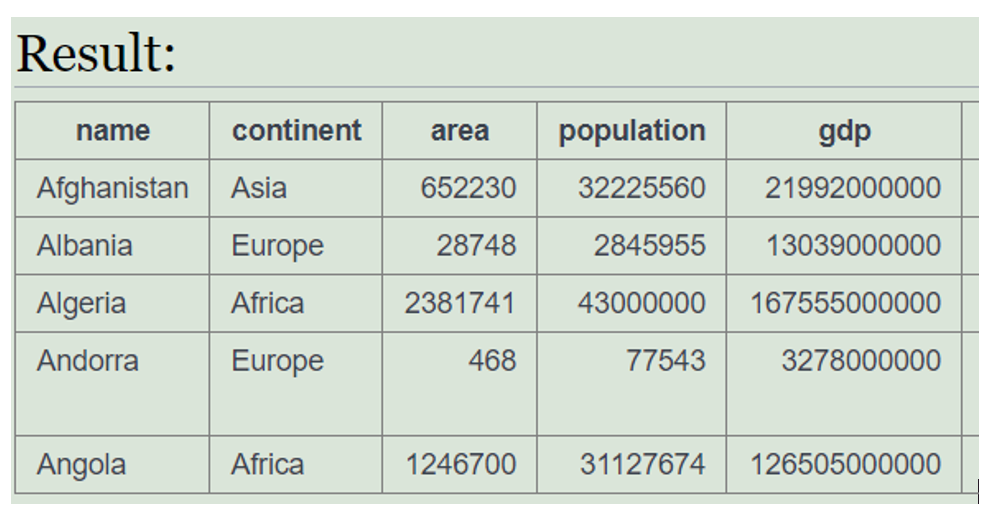
The above query selects 5 rows from the world table, if we want to look at all entries at once we can simple remove limit 5 from above query.
If we want to check on which column world table is unique at, we can achieve this by counting all the rows and counting the distinct entries of the particular column which we feel the table should be unique at. If both the counts are equal, we can say that the table is unique at that column. We can assume here the world table is unique at name column which is basically the country name, and our assumptions would be correct if we get same count for all the rows and distinct countries.


COUNT(*) gives count of all the entries in world table whereas COUNT(DISTINCT name) gives count of distinct name (country name) in the world table. We can assign names to these counts by using AS syntax like we have done in the above query.
We found that total entries and count of unique countries are same, hence our assumption was correct that the world table is unique at name column, or in other word, we have only one row for each country.
WHERE & AGGREGATE FUNCTIONS (COUNT, SUM, MAX, MIN, AVG)
WHERE is used to filer the table on some specific conditions whereas aggregate functions like count, sum (for total), min (for Minimum), max (for Maximum) and avg (for Average) are used to find aggregate outcomes.

Result of the above query is below:

With the help of aggregate functions, we are able to obtain total number of countries, total, minimum, maximum and average population of the world.
Let’s say we want to compare world’s population numbers with Asia continent, that’s when WHERE comes into picture and we can simply add Asia in the where condition of the above query to obtain required results.

The obtained result for Asia continent is below:

Few of the insights from above analysis are:
- There are total of 195 countries in the world table out of which 47 belongs to Asia continent
- Average population of the Asia (98 M) is higher than the World average population (39 M), this can be due to the fact that two of the most populous countries China and India belong to Asia
GROUP BY & HAVING
From above analysis, we compared world population numbers with Asia continent, what if we have to compare population or GDP numbers across different continents. For a single comparison above, we wrote two queries and if we have to compare 7 continents based on population or GDP, we would have to write many queries to obtain numbers. This is when GROUP BY comes to the rescue.
Group by aggregates the point of interest columns in our case population or GDP, based on the columns we want it to aggregate which is continent in our case.
We can perform group by on the basis of single or multiple columns but one thing to keep in mind is that we would have to include those columns in the select statement as well.
Above we discussed how WHERE statement is used to filter out the table, in the same way HAVING statement is used to filter out the results of a GROUP BY query. Enough said, let’s understand these concepts through example.

From above query you can see that we have applied the same aggregate functions used earlier but a simple inclusion of GROUP BY makes the whole lot of difference.
Here, the population has been group by continent so we have included continent in the select statement as well.
Below is the result of the above query:
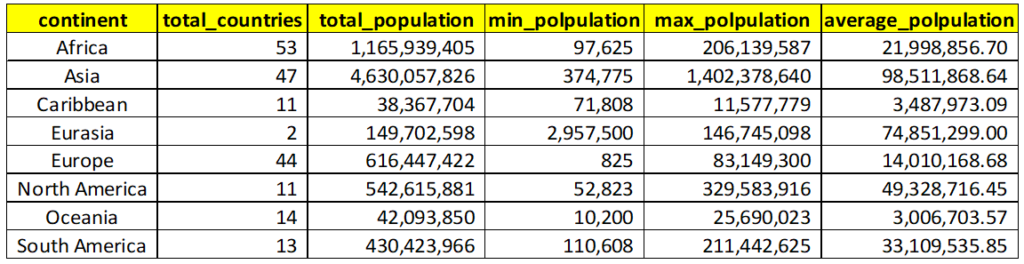
You can now observe the power of group by, a single query is able to obtain so much of information and we can compare population statistics across all continents from this single result.
Few of the insights that this powerful query gave are:
- Africa continent has the highest countries among all continents that is 53, whereas Asia and Europe come at second and third place with the numbers 47 and 44 respectively
- Asia’s total and average population is highest among all continents, whereas Africa comes at the second place
- Highest populous country is present in Asia which can be seen from max_population column whereas the lowest populous country is present in Europe continent which can be seen from min_population column
What if we are told to compare the results of only those continents which has at least 40 countries in it, from above result we can see that our final output should contain Africa, Asia and Europe but how do we get this?
This is when HAVING is used, it is used to filter out the results of the GROUP BY statement just like WHERE was used to filter out the base table (in our case world table).

Result of the above query is below:

We got the results we wanted by simply including HAVING statement at the end in the same query. HAVING is executed after the GROUP BY statement and slices the result of GROUP BY query based on the condition provided in the HAVING clause.
In the above query, the requirement was to get the population statistics of those continents only which has at least 40 countries in it, and if you see we have used total_countries>=40 in the HAVING clause, which is nothing but the count(name) which is aliased total_countries with the AS clause and count(name) is same as counting the number of countries. And this count will be obtained continent-wise because we have GROUP BY (or aggregated) on continent, so in this way you understand the flow of query execution and final information retrieval as per our requirement.
WHERE VS HAVING
WHERE is used to filter/slice the base table/tables in our case which is world table whereas HAVING is used to slice/filter the results of GROUP BY statements. Base table is not equivalent to GROUP BY query results and that is why HAVING should always be preceded by GROUP BY meaning if there is no GROUP BY, there is no HAVING.
If in the above query we would use WHERE instead of HAVING, we would get error. Let’s see this.

If we use this query, we would get below error:

WHERE can be used along with GROUP BY but it should be used before GROUP BY statement not after it as we have used in the above query which gave error.
For example, if the requirement is to get the population statistics at continent level but we should take into consideration only the countries which has gdp>=10 Billion, then we can use WHERE along with GROUP BY.
Below is the query and results as per new requirement:

Here, you can see that WHERE has been used along with GROUP BY but it is used before it not after and hence the query is valid and it will run in the following sequence:
- From world table, this query will filter out those countries which has gdp<10 Billion
- Now, our base table will become small and hence the population statistics and countries in each continent will be low because some of the countries from each continent may have less than 10 B gdp
- After it, the GROUP BY will be executed on the reduced data and population statistics will be calculated at continent level
Below is the result of the above query:
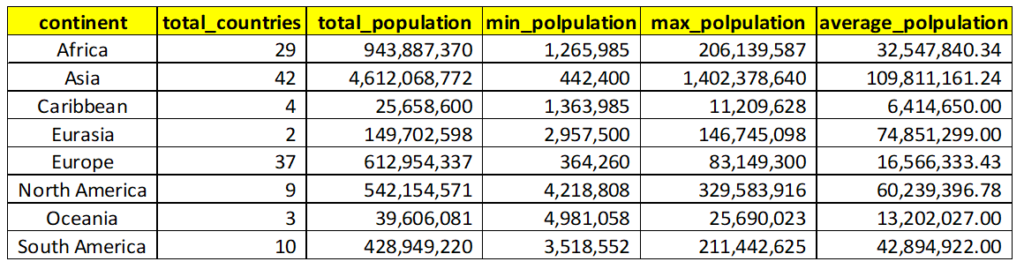
We can see from the total_countries column that the countries in each continent has reduced.
Africa continent used to have 53 countries but now it has only 29 countries, which implies 24 (53-29) countries in the Africa continent have gdp less than 10 Billion.
[References]: https://sqlzoo.net/ for dataset and code window