NATURAL LANGUAGE PROCESSING(NLP)
Natural Language Processing (NLP) is a field in Artificial Intelligence, and is also related to linguistics. On a high level, the goal of NLP is to program computers to automatically understand human languages, and also to automatically write/speak in human languages. We say “Natural Language” to mean human language, and to indicate that we are not talking about computer (programming) languages.
Structured Data Vs Unstructured Data
Structured data is data that has been organized into a formatted repository, typically a database, so that its elements can be made addressable for more effective processing and analysis. For the most part, structured data refers to information with a high degree of organization.
Unstructured data represents any data that does not have a recognizable structure. It is unorganized and raw and can be non-textual or textual. For example, email is a fine illustration of unstructured textual data. It includes time, date, recipient and sender details and subject, etc., but an email body remains unstructured.
Today, with digitization of everything, 80% of the data being created is unstructured. Audio, video, our social footprints, the data generated from conversations between customer service reps, tons of legal documents, and texts processed in financial sectors are examples of unstructured data. Organizations are turning to natural language processing (NLP) technology to derive understanding from the myriad unstructured data available online, in call logs, and in other sources.
Applications of NLP
Here are a few real world usages of NLP today:
1) Spell check functionality in Microsoft Word is the most basic and well-known application.
2) Text analysis, also known as sentiment analytics, is a key use of NLP. Businesses can use it to learn how their customers feel emotionally and use that data to improve their service.
3) By using email filters to analyze the emails that flow through their servers, email providers can use Naive Bayes spam filtering to calculate the likelihood that an email is spam based its content.
4) Call center representatives often hear the same, specific complaints, questions, and problems from customers. Mining this data for sentiment can produce incredibly actionable intelligence that can be applied to product placement, messaging, design, or a range of other uses.
5) Google, Bing, and other search systems use NLP to extract terms from text to populate their indexes and parse search queries.
6) Google Translate applies machine translation technologies in not only translating words, but also in understanding the meaning of sentences to improve translations.
7) Financial markets use NLP by taking plain-text announcements and extracting the relevant info in a format that can be factored into making algorithmic trading decisions. For example, news of a merger between companies can have a big impact on trading decisions, and the speed at which the particulars of the merger (e.g., players, prices, who acquires who) can be incorporated into a trading algorithm can have profit implications in the millions of dollars.
8) Nowadays NLP is widely used in chatbot development
NATURAL LANGUAGE TOOLKIT (NLTK)
The NLTK module is a massive tool kit, aimed at helping you with the entire Natural Language Processing (NLP) methodology. NLTK will aid you with everything from splitting sentences from paragraphs, splitting up words, recognizing the part of speech of those words, highlighting the main subjects, and then even with helping your machine to understand what the text is all about.In our path to learning how to do sentiment analysis with NLTK, we’re going to learn the following:
- Installation of NLTK
- Basic of NLTK ( Corpus, Lexicon, Token)
- Tokenization
- Stop Words
- Stemming words
- Parts of speech tagging
- Chunking
- Chinking
- Name Identity Recognition
- Lemmatizing
- Corpora
- Wordnet
- Text Classification
- Converting words to features
- Bag of words
- Document Term Matrix
- Word Embedding
- Text matching/Similarity
1. INSTALLATION OF NLTK
In order to get started, you are going to need the NLTK module, as well as Python. If you do not have Python yet, go to Python.org and download the latest version of Python if you are on Windows. If you are on Mac or Linux, you should be able to run an apt-get install python3
Next, you’re going to need NLTK 3. The easiest method to installing the NLTK module is going to be with pip.
For all users, that is done by opening up cmd.exe, bash, or whatever shell you use and typing: pip install nltk
Next, we need to install some of the components for NLTK. Open python via whatever means you normally do, and type:
import nltk
nltk.download()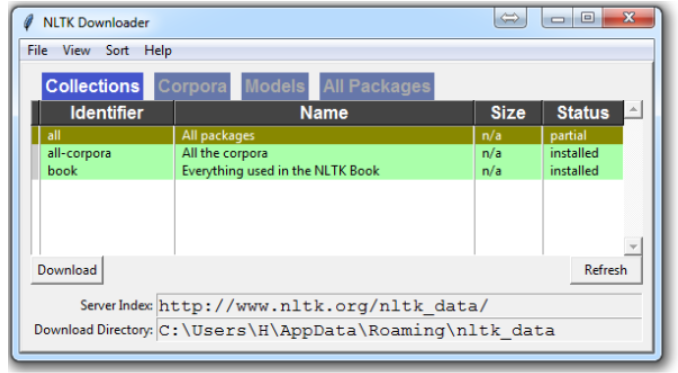
Note: Choose to download “all” for all packages, and then click ‘download.’ This will give you all of the tokenizers, chunkers, other algorithms, and all of the corpora. If space is an issue, you can elect to selectively download everything manually. The NLTK module will take up about 7MB, and the entire nltk_data directory will take up about 1.8GB, which includes your chunkers, parsers, and the corpora
2. BASICS OF NLTK ( Corpus, Lexicon, Token)
Now that you have all the things that you need, let’s knock out some quick vocabulary:
Corpus – Corpus basically means a body, and in the context of Natural Language Processing (NLP), it means a body of text.
Corpora – It is the plural for corpus.
Lexicon – Words and their meanings. Example: English dictionary. Consider, however, that various fields will have different lexicons. For example: To a financial investor, the first meaning for the word “Bull” is someone who is confident about the market, as compared to the common English lexicon, where the first meaning for the word “Bull” is an animal . As such there is a special lexicon for financial investors, doctors, children, mechanics, and so on.
Token – Each “entity” that is a part of whatever was split up based on rules. For examples, each word is a token when a sentence is “tokenized” into words. Each sentence can also be a token, if you tokenized the sentences out of a paragraph.
3. TOKENIZATION
Example of how one might actually tokenize something into tokens with the NLTK module:
from nltk.tokenize import sent_tokenize, word_tokenize
EXAMPLE_TEXT = "Hello Mr. Smith, how are you doing today? The weather is great, and Python is awesome. The sky is pinkish-blue. You shouldn't eat cardboard."
print(sent_tokenize(EXAMPLE_TEXT))['Hello Mr. Smith, how are you doing today?', 'The weather is great, and Python is awesome.', 'The sky is pinkish-blue.', "You shouldn't eat cardboard."]The above code will output the sentences, split up into a list of sentences, which you can do things like iterate through with a for loop. [‘Hello Mr. Smith, how are you doing today?’, ‘The weather is great, and Python is awesome.’, ‘The sky is pinkish-blue.’, “You shouldn’t eat cardboard.”]
So there, we have created tokens, which are sentences. Let’s tokenize by word instead this time:
print(word_tokenize(EXAMPLE_TEXT))['Hello', 'Mr.', 'Smith', ',', 'how', 'are', 'you', 'doing', 'today', '?', 'The', 'weather', 'is', 'great', ',', 'and', 'Python', 'is', 'awesome', '.', 'The', 'sky', 'is', 'pinkish-blue', '.', 'You', 'should', "n't", 'eat', 'cardboard', '.']There are a few things to note here. First, notice that punctuation is treated as a separate token. Also, notice the separation of the word “shouldn’t” into “should” and “n’t.” Finally, notice that “pinkish-blue” is indeed treated like the “one word” it was meant to be turned into. Pretty cool!
Now, looking at these tokenized words, we have to begin thinking about what our next step might be. We start to ponder about how might we derive meaning by looking at these words. We can clearly think of ways to put value to many words, but we also see a few words that are basically worthless.
4. STOP WORDS
The idea of Natural Language Processing is to do some form of analysis, or processing, where the machine can understand, at least to some level, what the text means, says, or implies.
This is an obviously massive challenge, but there are steps to doing it that anyone can follow. The main idea, however, is that computers simply do not, and will not, ever understand words directly.In humans, memory is broken down into electrical signals in the brain, in the form of neural groups that fire in patterns. There is a lot about the brain that remains unknown, but, the more we break down the human brain to the basic elements, we find out basic the elements really are. Well, it turns out computers store information in a very similar way! We need a way to get as close to that as possible if we’re going to mimic how humans read and understand text. Generally, computers use numbers for everything, but we often see directly in programming where we use binary signals (True or False, which directly translate to 1 or 0, which originates directly from either the presence of an electrical signal (True, 1), or not (False, 0)). To do this, we need a way to convert words to values, in numbers, or signal patterns. The process of converting data to something a computer can understand is referred to as “pre-processing.” One of the major forms of pre-processing is going to be filtering out useless data. In natural language processing, useless words (data), are referred to as stop words.
Immediately, we can recognize ourselves that some words carry more meaning than other words. We can also see that some words are just plain useless, and are filler words. We use them in the English language, for example, to sort of “fluff” up the sentence so it is not so strange sounding. An example of one of the most common, unofficial, useless words is the phrase “umm.” People stuff in “umm” frequently, some more than others. This word means nothing, unless of course we’re searching for someone who is maybe lacking confidence, is confused, or hasn’t practiced much speaking. We all do it, you can hear me saying “umm” or “uhh” in the videos plenty of …uh … times. For most analysis, these words are useless.
We would not want these words taking up space in our database, or taking up valuable processing time. As such, we call these words “stop words” because they are useless, and we wish to do nothing with them. Another version of the term “stop words” can be more literal: Words we stop on.
For example, you may wish to completely cease analysis if you detect words that are commonly used sarcastically, and stop immediately. Sarcastic words, or phrases are going to vary by lexicon and corpus. For now, we’ll be considering stop words as words that just contain no meaning, and we want to remove them.
You can do this easily, by storing a list of words that you consider to be stop words. NLTK starts you off with a bunch of words that they consider to be stop words, you can access it via the NLTK corpus with:
from nltk.corpus import stopwordsfrom nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
example_sent = "This is a sample sentence, showing off the stop words filtration."
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(example_sent)
filtered_sentence = [w for w in word_tokens if not w in stop_words]
filtered_sentence = []
for w in word_tokens:
if w not in stop_words:
filtered_sentence.append(w)
print(word_tokens)
print(filtered_sentence)['This', 'is', 'a', 'sample', 'sentence', ',', 'showing', 'off', 'the', 'stop', 'words', 'filtration', '.']
['This', 'sample', 'sentence', ',', 'showing', 'stop', 'words', 'filtration', '.']5. STEMMING
The idea of stemming is a sort of normalizing method. Many variations of words carry the same meaning, other than when tense is involved.
The reason why we stem is to shorten the lookup, and normalize sentences.
Consider:
I was taking a ride in the car. I was riding in the car. This sentence means the same thing. in the car is the same. I was is the same. the ing denotes a clear past-tense in both cases, so is it truly necessary to differentiate between ride and riding, in the case of just trying to figure out the meaning of what this past-tense activity was?
No, not really.
This is just one minor example, but imagine every word in the English language, every possible tense and affix you can put on a word. Having individual dictionary entries per version would be highly redundant and inefficient, especially since, once we convert to numbers, the “value” is going to be identical.
One of the most popular stemming algorithms is the Porter stemmer, which has been around since 1979.
First, we’re going to grab and define our stemmer:
from nltk.stem import PorterStemmer
from nltk.tokenize import sent_tokenize, word_tokenize
ps = PorterStemmer()example_words = ["python","pythoner","pythoning","pythoned","pythonly"]Above we chose some words with a similar stem. Next, we can easily stem by doing something like:
for w in example_words:
print(ps.stem(w))python
python
python
python
pythonliNow let’s try stemming a typical sentence, rather than some words:
new_text = "It is important to by very pythonly while you are pythoning with python. All pythoners have pythoned poorly at least once."words = word_tokenize(new_text)
for w in words:
print(ps.stem(w))It
is
import
to
by
veri
pythonli
while
you
are
python
with
python
.
all
python
have
python
poorli
at
least
onc6. PARTS OF SPEECH TAGGING
One of the more powerful aspects of the NLTK module is the Part of Speech tagging that it can do for you. This means labeling words in a sentence as nouns, adjectives, verbs…etc. Even more impressive, it also labels by tense, and more. Here’s a list of the tags, what they mean, and some examples:
POS tag list:
CC coordinating conjunction
CD cardinal digit
DT determiner
EX existential there (like: "there is" ... think of it like "there exists")
FW foreign word
IN preposition/subordinating conjunction
JJ adjective 'big'
JJR adjective, comparative 'bigger'
JJS adjective, superlative 'biggest'
LS list marker 1)
MD modal could, will
NN noun, singular 'desk'
NNS noun plural 'desks'
NNP proper noun, singular 'Harrison'
NNPS proper noun, plural 'Americans'
PDT predeterminer 'all the kids'
POS possessive ending parent\'s
PRP personal pronoun I, he, she
PRP$ possessive pronoun my, his, hers
RB adverb very, silently,
RBR adverb, comparative better
RBS adverb, superlative best
RP particle give up
TO to go 'to' the store.
UH interjection errrrrrrrm
VB verb, base form take
VBD verb, past tense took
VBG verb, gerund/present participle taking
VBN verb, past participle taken
VBP verb, sing. present, non-3d take
VBZ verb, 3rd person sing. present takes
WDT wh-determiner which
WP wh-pronoun who, what
WP$ possessive wh-pronoun whose
WRB wh-abverb where, whenHow might we use this? While we’re at it, we’re going to cover a new sentence tokenizer, called the PunktSentenceTokenizer. This tokenizer is capable of unsupervised machine learning, so you can actually train it on any body of text that you use. First, let’s get some imports out of the way that we’re going to use:
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizerNow, let’s create our training and testing data
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")One is a State of the Union address from 2005, and the other is from 2006 from past President George W. Bush.
Next, we can train the Punkt tokenizer like:
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)Then we can actually tokenize, using:
tokenized = custom_sent_tokenizer.tokenize(sample_text)Now we can finish up this part of speech tagging script by creating a function that will run through and tag all of the parts of speech per sentence like so:
def process_content():
try:
for i in tokenized[:5]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
print(tagged)
except Exception as e:
print(str(e))
process_content()[('PRESIDENT', 'NNP'), ('GEORGE', 'NNP'), ('W.', 'NNP'), ('BUSH', 'NNP'), ("'S", 'POS'), ('ADDRESS', 'NNP'), ('BEFORE', 'IN'), ('A', 'NNP'), ('JOINT', 'NNP'), ('SESSION', 'NNP'), ('OF', 'IN'), ('THE', 'NNP'), ('CONGRESS', 'NNP'), ('ON', 'NNP'), ('THE', 'NNP'), ('STATE', 'NNP'), ('OF', 'IN'), ('THE', 'NNP'), ('UNION', 'NNP'), ('January', 'NNP'), ('31', 'CD'), (',', ','), ('2006', 'CD'), ('THE', 'NNP'), ('PRESIDENT', 'NNP'), (':', ':'), ('Thank', 'NNP'), ('you', 'PRP'), ('all', 'DT'), ('.', '.')]
[('Mr.', 'NNP'), ('Speaker', 'NNP'), (',', ','), ('Vice', 'NNP'), ('President', 'NNP'), ('Cheney', 'NNP'), (',', ','), ('members', 'NNS'), ('of', 'IN'), ('Congress', 'NNP'), (',', ','), ('members', 'NNS'), ('of', 'IN'), ('the', 'DT'), ('Supreme', 'NNP'), ('Court', 'NNP'), ('and', 'CC'), ('diplomatic', 'JJ'), ('corps', 'NN'), (',', ','), ('distinguished', 'JJ'), ('guests', 'NNS'), (',', ','), ('and', 'CC'), ('fellow', 'JJ'), ('citizens', 'NNS'), (':', ':'), ('Today', 'VB'), ('our', 'PRP$'), ('nation', 'NN'), ('lost', 'VBD'), ('a', 'DT'), ('beloved', 'VBN'), (',', ','), ('graceful', 'JJ'), (',', ','), ('courageous', 'JJ'), ('woman', 'NN'), ('who', 'WP'), ('called', 'VBD'), ('America', 'NNP'), ('to', 'TO'), ('its', 'PRP$'), ('founding', 'NN'), ('ideals', 'NNS'), ('and', 'CC'), ('carried', 'VBD'), ('on', 'IN'), ('a', 'DT'), ('noble', 'JJ'), ('dream', 'NN'), ('.', '.')]
[('Tonight', 'NN'), ('we', 'PRP'), ('are', 'VBP'), ('comforted', 'VBN'), ('by', 'IN'), ('the', 'DT'), ('hope', 'NN'), ('of', 'IN'), ('a', 'DT'), ('glad', 'JJ'), ('reunion', 'NN'), ('with', 'IN'), ('the', 'DT'), ('husband', 'NN'), ('who', 'WP'), ('was', 'VBD'), ('taken', 'VBN'), ('so', 'RB'), ('long', 'RB'), ('ago', 'RB'), (',', ','), ('and', 'CC'), ('we', 'PRP'), ('are', 'VBP'), ('grateful', 'JJ'), ('for', 'IN'), ('the', 'DT'), ('good', 'JJ'), ('life', 'NN'), ('of', 'IN'), ('Coretta', 'NNP'), ('Scott', 'NNP'), ('King', 'NNP'), ('.', '.')]
[('(', '('), ('Applause', 'NNP'), ('.', '.'), (')', ')')]
[('President', 'NNP'), ('George', 'NNP'), ('W.', 'NNP'), ('Bush', 'NNP'), ('reacts', 'VBZ'), ('to', 'TO'), ('applause', 'VB'), ('during', 'IN'), ('his', 'PRP$'), ('State', 'NNP'), ('of', 'IN'), ('the', 'DT'), ('Union', 'NNP'), ('Address', 'NNP'), ('at', 'IN'), ('the', 'DT'), ('Capitol', 'NNP'), (',', ','), ('Tuesday', 'NNP'), (',', ','), ('Jan', 'NNP'), ('.', '.')]The output should be a list of tuples, where the first element in the tuple is the word, and the second is the part of speech tag
At this point, we can begin to derive meaning, but there is still some work to do. The next topic that we’re going to cover is chunking, which is where we group words, based on their parts of speech, into hopefully meaningful groups.
7. CHUNKING
Now that we know the parts of speech, we can do what is called chunking, and group words into hopefully meaningful chunks. One of the main goals of chunking is to group into what are known as “noun phrases.” These are phrases of one or more words that contain a noun, maybe some descriptive words, maybe a verb, and maybe something like an adverb. The idea is to group nouns with the words that are in relation to them.
+ = match 1 or more
? = match 0 or 1 repetitions.
* = match 0 or MORE repetitions
. = Any character except a new lineThe last things to note is that the part of speech tags are denoted with the “<” and “>” and we can also place regular expressions within the tags themselves, so account for things like “all nouns” (<N.*>)
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
chunked.draw()
except Exception as e:
print(str(e))
process_content()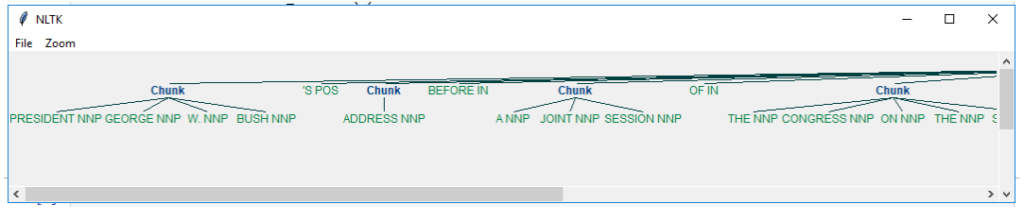
The main line here in question is:
chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""This line, broken down:
<RB.?>* = “0 or more of any tense of adverb,” followed by:
<VB.?>* = “0 or more of any tense of verb,” followed by:
+ = “One or more proper nouns,” followed by
? = “zero or one singular noun.”
8. CHINKING
You may find that, after a lot of chunking, you have some words in your chunk you still do not want, but you have no idea how to get rid of them by chunking. You may find that chinking is your solution.
Chinking is a lot like chunking, it is basically a way for you to remove a chunk from a chunk. The chunk that you remove from your chunk is your chink.
The code is very similar, you just denote the chink, after the chunk, with }{ instead of the chunk’s {}.
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized[5:]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
chunkGram = r"""Chunk: {<.*>+}
}<VB.?|IN|DT|TO>+{"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
chunked.draw()
except Exception as e:
print(str(e))
process_content()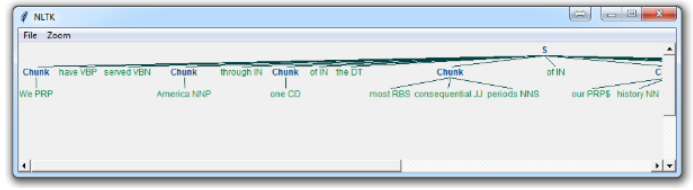
Now, the main difference here is:
}<VB.?|IN|DT|TO>+{This means we’re removing from the chink one or more verbs, prepositions, determiners, or the word ‘to’.
Now that we’ve learned how to do some custom forms of chunking, and chinking, let’s discuss a built-in form of chunking that comes with NLTK, and that is named entity recognition.
9. NAME IDENTITY RECOGNITION
One of the most major forms of chunking in natural language processing is called “Named Entity Recognition.” The idea is to have the machine immediately be able to pull out “entities” like people, places, things, locations, monetary figures, and more.
This can be a bit of a challenge, but NLTK is this built in for us. There are two major options with NLTK’s named entity recognition: either recognize all named entities, or recognize named entities as their respective type, like people, places, locations, etc.
Here’s an example:
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized[5:]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
namedEnt = nltk.ne_chunk(tagged, binary=True)
namedEnt.draw()
except Exception as e:
print(str(e))
process_content()Here, with the option of binary = True, this means either something is a named entity, or not. There will be no further detail. The result is:
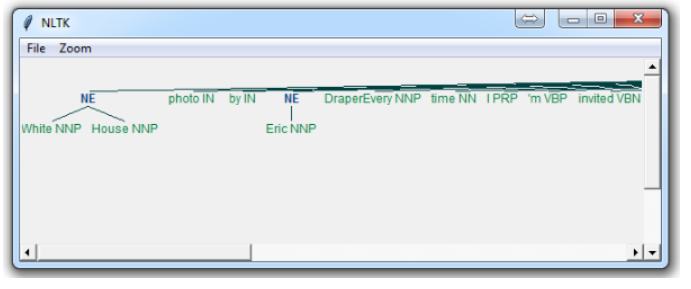
If you set binary = False, then the result is:
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized[5:]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
namedEnt = nltk.ne_chunk(tagged, binary=False)
namedEnt.draw()
except Exception as e:
print(str(e))
process_content()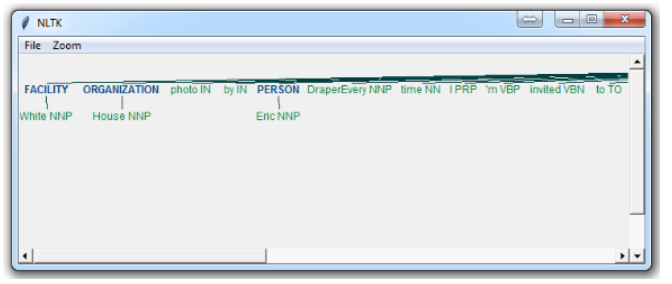
Immediately, you can see a few things. When Binary is False, it picked up the same things, but wound up splitting up terms like White House into “White” and “House” as if they were different, whereas we could see in the binary = True option, the named entity recognition was correct to say White House was part of the same named entity.
Depending on your goals, you may use the binary option how you see fit. Here are the types of Named Entities that you can get if you have binary as false:
NE Type and Examples:
ORGANIZATION – Georgia-Pacific Corp., WHO
PERSON – Eddy Bonte, President Obama
LOCATION – Murray River, Mount Everest
DATE – June, 2008-06-29
TIME – two fifty a m, 1:30 p.m.
MONEY – 175 million Canadian Dollars, GBP 10.40
PERCENT – twenty pct, 18.75 %
FACILITY – Washington Monument, Stonehenge
GPE – South East Asia, Midlothian
10. Lemmatization
A very similar operation to stemming is called lemmatizing. The major difference between these is, as you saw earlier, stemming can often create non-existent words, whereas lemmas are actual words.
So, your root stem, meaning the word you end up with, is not something you can just look up in a dictionary, but you can look up a lemma.
Some times you will wind up with a very similar word, but sometimes, you will wind up with a completely different word. Let’s see some examples.
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize("cats"))
print(lemmatizer.lemmatize("cacti"))
print(lemmatizer.lemmatize("geese"))
print(lemmatizer.lemmatize("rocks"))
print(lemmatizer.lemmatize("python"))
print(lemmatizer.lemmatize("better", pos="a"))
print(lemmatizer.lemmatize("best", pos="a"))
print(lemmatizer.lemmatize("run"))
print(lemmatizer.lemmatize("run",'v'))cat
cactus
goose
rock
python
good
best
run
run*Note: *Here, we’ve got a bunch of examples of the lemma for the words that we use. The only major thing to note is that lemmatize takes a part of speech parameter, “pos.” If not supplied, the default is “noun.” This means that an attempt will be made to find the closest noun, which can create trouble for you. Keep this in mind if you use lemmatizing!
11. CORPORA
The NLTK corpus is a massive dump of all kinds of natural language data sets that are definitely worth taking a look at.
Almost all of the files in the NLTK corpus follow the same rules for accessing them by using the NLTK module, but nothing is magical about them. These files are plain text files for the most part, some are XML and some are other formats, but they are all accessible by you manually, or via the module and Python. Let’s talk about viewing them manually.
Depending on your installation, your nltk_data directory might be hiding in a multitude of locations. To figure out where it is, head to your Python directory, where the NLTK module is. If you do not know where that is, use the following code:
import nltk
print(nltk.__file__)C:\Users\divya\Anaconda3\lib\site-packages\nltk\__init__.pyThe important blurb of code is:
if sys.platform.startswith('win'):
# Common locations on Windows:
path += [
str(r'C:\nltk_data'), str(r'D:\nltk_data'), str(r'E:\nltk_data'),
os.path.join(sys.prefix, str('nltk_data')),
os.path.join(sys.prefix, str('lib'), str('nltk_data')),
os.path.join(os.environ.get(str('APPDATA'), str('C:\\')), str('nltk_data'))
]
else:
# Common locations on UNIX & OS X:
path += [
str('/usr/share/nltk_data'),
str('/usr/local/share/nltk_data'),
str('/usr/lib/nltk_data'),
str('/usr/local/lib/nltk_data')
]There, you can see the various possible directories for the nltk_data. If you’re on Windows, chances are it is in your appdata, in the local directory. To get there, you will want to open your file browser, go to the top, and type in %appdata%
Next click on roaming, and then find the nltk_data directory. In there, you will have your corpora file. The full path is something like: C:\Users\yourname\AppData\Roaming\nltk_data\corpora
Within here, you have all of the available corpora, including things like books, chat logs, movie reviews, and a whole lot more.
Now, we’re going to talk about accessing these documents via NLTK. As you can see, these are mostly text documents, so you could just use normal Python code to open and read documents. That said, the NLTK module has a few nice methods for handling the corpus, so you may find it useful to use their methology. Here’s an example of us opening the Gutenberg Bible, and reading the first few lines:
from nltk.tokenize import sent_tokenize, PunktSentenceTokenizer
from nltk.corpus import gutenberg
# sample text
sample = gutenberg.raw("bible-kjv.txt")
tok = sent_tokenize(sample)
for x in range(5):
print(tok[x])[The King James Bible] The Old Testament of the King James Bible The First Book of Moses: Called Genesis 1:1 In the beginning God created the heaven and the earth. 1:2 And the earth was without form, and void; and darkness was upon the face of the deep. And the Spirit of God moved upon the face of the waters. 1:3 And God said, Let there be light: and there was light. 1:4 And God saw the light, that it was good: and God divided the light from the darkness.
12. WORDNET
WordNet is a lexical database for the English language, which was created by Princeton, and is part of the NLTK corpus.
You can use WordNet alongside the NLTK module to find the meanings of words, synonyms, antonyms, and more. Let’s cover some examples.
First, you’re going to need to import wordnet:
from nltk.corpus import wordnetThen, we’re going to use the term “program” to find synsets like so:
syns = wordnet.synsets("program")An example of a synset:
print(syns[0].name())plan.n.01
print(syns[0].lemmas()[0].name())plan
Definition of that first synset:
print(syns[0].definition())a series of steps to be carried out or goals to be accomplished
Examples of the word in use:
print(syns[0].examples())['they drew up a six-step plan', 'they discussed plans for a new bond issue']
Next, how might we discern synonyms and antonyms to a word? The lemmas will be synonyms, and then you can use .antonyms to find the antonyms to the lemmas. As such, we can populate some lists like
synonyms = []
antonyms = []
for syn in wordnet.synsets("good"):
for l in syn.lemmas():
synonyms.append(l.name())
if l.antonyms():
antonyms.append(l.antonyms()[0].name())
print(set(synonyms)){'respectable', 'upright', 'good', 'beneficial', 'honest', 'expert', 'unspoiled', 'estimable', 'adept', 'safe', 'goodness', 'thoroughly', 'soundly', 'effective', 'skillful', 'near', 'unspoilt', 'just', 'commodity', 'full', 'skilful', 'dependable', 'in_force', 'serious', 'salutary', 'sound', 'undecomposed', 'ripe', 'secure', 'in_effect', 'proficient', 'well', 'right', 'honorable', 'trade_good', 'practiced', 'dear'}
{'evilness', 'evil', 'bad', 'ill', 'badness'}
As you can see, we got many more synonyms than antonyms, since we just looked up the antonym for the first lemma, but you could easily balance this buy also doing the exact same process for the term “bad.”
Next, we can also easily use WordNet to compare the similarity of two words and their tenses, by incorporating the Wu and Palmer method for semantic related-ness.
Let’s compare the noun of “ship” and “boat:”
w1 = wordnet.synset('ship.n.01')
w2 = wordnet.synset('boat.n.01')
print(w1.wup_similarity(w2))0.9090909090909091
Compare ship and car:
w1 = wordnet.synset('ship.n.01')
w2 = wordnet.synset('car.n.01')
print(w1.wup_similarity(w2))0.6956521739130435
Compare ship and cat :
w1 = wordnet.synset('ship.n.01')
w2 = wordnet.synset('cat.n.01')
print(w1.wup_similarity(w2))0.32
13. TEXT CLASSIFICATION
Now that we’re comfortable with NLTK, let’s try to tackle text classification. The goal with text classification can be pretty broad. Maybe we’re trying to classify text as about politics or the military. Maybe we’re trying to classify it by the gender of the author who wrote it. A fairly popular text classification task is to identify a body of text as either spam or not spam, for things like email filters. In our case, we’re going to try to create a sentiment analysis algorithm.
To do this, we’re going to start by trying to use the movie reviews database that is part of the NLTK corpus. From there we’ll try to use words as “features” which are a part of either a positive or negative movie review. The NLTK corpus movie_reviews data set has the reviews, and they are labeled already as positive or negative. This means we can train and test with this data. First, let’s wrangle our data.
import nltk
import random
from nltk.corpus import movie_reviews
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
print(documents[1])
all_words = []
for w in movie_reviews.words():
all_words.append(w.lower())
all_words = nltk.FreqDist(all_words)
print(all_words.most_common(15))
print(all_words["stupid"])(['lean', ',', 'mean', ',', 'escapist', 'thrillers', 'are', 'a', 'tough', 'product', 'to', 'come', 'by', '.', 'most', 'are', 'unnecessarily', 'complicated', ',', 'and', 'others', 'have', 'no', 'sense', 'of', 'expediency', '--', 'the', 'thrill', '-', 'ride', 'effect', 'gets', 'lost', 'in', 'the', 'cumbersome', 'plot', '.', 'perhaps', 'the', 'ultimate', 'escapist', 'thriller', 'was', 'the', 'fugitive', ',', 'which', 'featured', 'none', 'of', 'the', 'flash', '-', 'bang', 'effects', 'of', 'today', "'", 's', 'market', 'but', 'rather', 'a', 'bread', '-', 'and', '-', 'butter', ',', 'textbook', 'example', 'of', 'what', 'a', 'clever', 'script', 'and', 'good', 'direction', 'is', 'all', 'about', '.', 'the', 'latest', 'tony', 'scott', 'movie', ',', 'enemy', 'of', 'the', 'state', ',', 'doesn', "'", 't', 'make', 'it', 'to', 'that', 'level', '.', 'it', "'", 's', 'a', 'true', 'nineties', 'product', 'that', 'runs', 'like', 'greased', 'lightning', 'through', 'a', 'maze', 'of', 'cell', 'phones', 'and', 'laptop', 'computers', ',', 'without', 'looking', 'back', '.', 'although', 'director', 'scott', 'has', 'made', 'missteps', 'in', 'the', 'past', ',', 'such', 'as', 'the', 'lame', 'thriller', 'the', 'fan', ',', 'he', "'", 's', 'generated', 'a', 'good', 'deal', 'of', 'energy', 'in', 'pictures', 'like', 'crimson', 'tide', 'and', 'top', 'gun', '.', 'that', 'vibrant', 'spirit', 'is', 'present', 'here', ',', 'shown', 'in', 'well', '-', 'timed', 'and', 'carefully', 'planned', 'chase', 'scenes', 'that', 'give', 'the', 'movie', 'an', 'aura', 'of', 'sheer', 'speed', '.', 'enemy', 'of', 'the', 'state', 'also', 'features', 'an', 'unprecedented', 'use', 'of', 'amazing', 'cinematography', '--', 'director', 'of', 'photography', 'daniel', 'mindel', 'throws', 'a', 'staggering', 'amount', 'of', 'different', 'views', ',', 'angles', ',', 'lenses', ',', 'and', 'film', 'stocks', 'at', 'the', 'audience', 'that', 'goes', 'a', 'long', 'way', 'toward', 'involving', 'the', 'audience', 'in', 'the', 'movie', '.', 'enemy', 'is', 'truly', 'a', 'visual', 'experience', ',', 'and', 'that', "'", 's', 'only', 'one', 'of', 'the', 'reasons', 'it', "'", 's', 'such', 'a', 'fun', 'watch', '.', 'the', 'movie', 'lights', 'up', 'with', 'an', 'aging', 'senator', 'visited', 'by', 'nsa', 'deputy', 'chief', 'thomas', 'reynolds', '(', 'jon', 'voight', ')', '.', 'reynolds', 'wants', 'a', 'new', 'communications', 'act', 'passed', 'to', 'allow', 'the', 'government', 'free', 'reign', 'in', 'the', 'use', 'of', 'surveilance', 'equipment', ',', 'but', 'the', 'senator', 'plans', 'to', 'bury', 'the', 'bill', 'in', 'committee', '.', 'reynolds', 'has', 'the', 'senator', 'offed', ',', 'but', 'not', 'before', 'the', 'murder', 'is', 'caught', 'on', 'a', 'naturalist', "'", 's', 'camera', '.', 'by', 'an', 'extremist', 'chain', 'of', 'events', ',', 'the', 'tape', 'ends', 'up', 'in', 'labor', 'lawyer', 'robert', 'dean', '(', 'will', 'smith', ')', "'", 's', 'posession', ',', 'and', 'it', "'", 's', 'not', 'long', 'before', 'he', "'", 's', 'running', 'from', 'reynolds', "'", 'cronies', '.', 'it', "'", 's', 'only', 'with', 'the', 'help', 'of', 'an', 'ex', '-', 'spook', 'named', 'brill', '(', 'gene', 'hackman', ')', 'that', 'dean', 'is', 'able', 'to', 'get', 'to', 'the', 'bottom', 'of', 'things', '.', 'the', 'acting', 'is', 'top', 'notch', ',', 'and', 'the', 'three', 'principles', '-', 'smith', ',', 'hackman', ',', 'and', 'voight', '-', 'are', 'generally', 'more', 'mature', 'and', 'excellent', 'all', 'around', '.', 'smith', 'puts', 'aside', 'the', 'wisecracking', 'act', 'and', 'becomes', 'a', 'normal', 'human', 'being', ';', 'voight', 'tones', 'down', 'the', 'amount', 'of', 'sneer', 'he', 'puts', 'into', 'his', 'character', 'for', 'greater', 'ominpotence', ';', 'and', 'hackman', 'is', 'simply', 'over', 'the', 'top', 'in', 'the', 'mysterioso', 'role', '.', 'smith', "'", 's', 'regular', 'joe', 'comes', 'off', 'particularly', 'well', ',', 'as', 'he', 'runs', 'from', 'authorties', 'for', 'reasons', 'that', 'he', 'knows', 'not', '.', 'the', 'supports', 'are', 'also', 'in', 'fine', 'form', ',', 'lending', 'credibility', 'to', 'the', 'main', 'roles', 'and', 'advancing', 'the', 'plot', 'in', 'key', 'areas', '.', 'this', 'is', ',', 'for', 'the', 'holiday', 'crowd', ',', 'the', 'hot', 'ticket', ';', 'as', 'well', 'as', 'anyone', 'looking', 'for', 'a', 'serving', 'of', 'genuine', 'action', 'in', 'a', 'market', 'that', 'is', 'otherwise', 'lacking', '.'], 'pos')
[(',', 77717), ('the', 76529), ('.', 65876), ('a', 38106), ('and', 35576), ('of', 34123), ('to', 31937), ("'", 30585), ('is', 25195), ('in', 21822), ('s', 18513), ('"', 17612), ('it', 16107), ('that', 15924), ('-', 15595)]
253
It may take a moment to run this script, as the movie reviews dataset is somewhat large. Let’s cover what is happening here.
After importing the data set we want, you see:
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]Basically, in plain English, the above code is translated to: In each category (we have pos or neg), take all of the file IDs (each review has its own ID), then store the word_tokenized version (a list of words) for the file ID, followed by the positive or negative label in one big list.
Next, we use random to shuffle our documents. This is because we’re going to be training and testing. If we left them in order, chances are we’d train on all of the negatives, some positives, and then test only against positives. We don’t want that, so we shuffle the data.
Then, just so you can see the data you are working with, we print out documents[1], which is a big list, where the first element is a list the words, and the 2nd element is the “pos” or “neg” label.
Next, we want to collect all words that we find, so we can have a massive list of typical words. From here, we can perform a frequency distribution, to then find out the most common words. As you will see, the most popular “words” are actually things like punctuation, “the,” “a” and so on, but quickly we get to legitimate words. We intend to store a few thousand of the most popular words, so this shouldn’t be a problem.
print(all_words.most_common(15))[(',', 77717), ('the', 76529), ('.', 65876), ('a', 38106), ('and', 35576), ('of', 34123), ('to', 31937), ("'", 30585), ('is', 25195), ('in', 21822), ('s', 18513), ('"', 17612), ('it', 16107), ('that', 15924), ('-', 15595)]
The above gives you the 15 most common words. You can also find out how many occurences a word has by doing:
print(all_words["stupid"])253
Next up, we’ll begin storing our words as features of either positive or negative movie reviews.
14. CONVERTING WORDS TO FEATURES
we are compiling the feature lists of words from positive reviews and words from the negative reviews to hopefully see trends in specific types of words in positive or negative reviews.
import nltk
import random
from nltk.corpus import movie_reviews
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
all_words = []
for w in movie_reviews.words():
all_words.append(w.lower())
all_words = nltk.FreqDist(all_words)
word_features = list(all_words.keys())[:3000]Mostly the same as before, only with now a new variable, word_features, which contains the top 3,000 most common words. Next, we’re going to build a quick function that will find these top 3,000 words in our positive and negative documents, marking their presence as either positive or negative:
def find_features(document):
words = set(document)
features = {}
for w in word_features:
features[w] = (w in words)
return featuresNext, we can print one feature set like:
print((find_features(movie_reviews.words('neg/cv000_29416.txt')))){'plot': True, ':': True, 'two': True, 'teen': True, 'couples': True, 'go': True, 'to': True, 'a': True, 'church': True, 'party': True, ',': True, 'drink': True, 'and': True, 'then': True, 'drive': True, '.': True, 'they': True, 'get': True, 'into': True, 'an': True, 'accident': True, 'one': True, 'of': True, 'the': True, 'guys': True, 'dies': True, 'but': True, 'his': True, 'girlfriend': True, 'continues': True, 'see': True, 'him': True, 'in': True, 'her': True, 'life': True, 'has': True, 'nightmares': True, 'what': True, "'": True, 's': True, 'deal': True, '?': True, 'watch': True, 'movie': True, '"': True, 'sorta': True, 'find': True, 'out': True, 'critique': True, 'mind': True, '-': True, 'fuck': True, 'for': True, 'generation': True, 'that': True, 'touches': True, 'on': True, 'very': True, 'cool': True, 'idea': True, 'presents': True, 'it': True, 'bad': True, 'package': True, 'which': True, 'is': True, 'makes': True, 'this': True, 'review': True, 'even': True, 'harder': True, 'write': True, 'since': True, 'i': True, 'generally': True, 'applaud': True, 'films': True, 'attempt': True, 'break': True, 'mold': True, 'mess': True, 'with': True, 'your': True, 'head': True, 'such': True, '(': True, 'lost': True, 'highway': True, '&': True, 'memento': True, ')': True, 'there': True, 'are': True, 'good': True, 'ways': True, 'making': True, 'all': True, 'types': True, 'these': True, 'folks': True, 'just': True, 'didn': True, 't': True, 'snag': True, 'correctly': True, 'seem': True, 'have': True, 'taken': True, 'pretty': True, 'neat': True, 'concept': True, 'executed': True, 'terribly': True, 'so': True, 'problems': True, 'well': True, 'its': True, 'main': True, 'problem': True, 'simply': True, 'too': True, 'jumbled': True, 'starts': True, 'off': True, 'normal': True, 'downshifts': True, 'fantasy': True, 'world': True, 'you': True, 'as': True, 'audience': True, 'member': True, 'no': True, 'going': True, 'dreams': True, 'characters': True, 'coming': True, 'back': True, 'from': True, 'dead': True, 'others': True, 'who': True, 'look': True, 'like': True, 'strange': True, 'apparitions': True, 'disappearances': True, 'looooot': True, 'chase': True, 'scenes': True, 'tons': True, 'weird': True, 'things': True, 'happen': True, 'most': True, 'not': True, 'explained': True, 'now': True, 'personally': True, 'don': True, 'trying': True, 'unravel': True, 'film': True, 'every': True, 'when': True, 'does': True, 'give': True, 'me': True, 'same': True, 'clue': True, 'over': True, 'again': True, 'kind': True, 'fed': True, 'up': True, 'after': True, 'while': True, 'biggest': True, 'obviously': True, 'got': True, 'big': True, 'secret': True, 'hide': True, 'seems': True, 'want': True, 'completely': True, 'until': True, 'final': True, 'five': True, 'minutes': True, 'do': True, 'make': True, 'entertaining': True, 'thrilling': True, 'or': True, 'engaging': True, 'meantime': True, 'really': True, 'sad': True, 'part': True, 'arrow': True, 'both': True, 'dig': True, 'flicks': True, 'we': True, 'actually': True, 'figured': True, 'by': True, 'half': True, 'way': True, 'point': True, 'strangeness': True, 'did': True, 'start': True, 'little': True, 'bit': True, 'sense': True, 'still': True, 'more': True, 'guess': True, 'bottom': True, 'line': True, 'movies': True, 'should': True, 'always': True, 'sure': True, 'before': True, 'given': True, 'password': True, 'enter': True, 'understanding': True, 'mean': True, 'showing': True, 'melissa': True, 'sagemiller': True, 'running': True, 'away': True, 'visions': True, 'about': True, '20': True, 'throughout': True, 'plain': True, 'lazy': True, '!': True, 'okay': True, 'people': True, 'chasing': True, 'know': True, 'need': True, 'how': True, 'giving': True, 'us': True, 'different': True, 'offering': True, 'further': True, 'insight': True, 'down': True, 'apparently': True, 'studio': True, 'took': True, 'director': True, 'chopped': True, 'themselves': True, 'shows': True, 'might': True, 've': True, 'been': True, 'decent': True, 'here': True, 'somewhere': True, 'suits': True, 'decided': True, 'turning': True, 'music': True, 'video': True, 'edge': True, 'would': True, 'actors': True, 'although': True, 'wes': True, 'bentley': True, 'seemed': True, 'be': True, 'playing': True, 'exact': True, 'character': True, 'he': True, 'american': True, 'beauty': True, 'only': True, 'new': True, 'neighborhood': True, 'my': True, 'kudos': True, 'holds': True, 'own': True, 'entire': True, 'feeling': True, 'unraveling': True, 'overall': True, 'doesn': True, 'stick': True, 'because': True, 'entertain': True, 'confusing': True, 'rarely': True, 'excites': True, 'feels': True, 'redundant': True, 'runtime': True, 'despite': True, 'ending': True, 'explanation': True, 'craziness': True, 'came': True, 'oh': True, 'horror': True, 'slasher': True, 'flick': True, 'packaged': True, 'someone': True, 'assuming': True, 'genre': True, 'hot': True, 'kids': True, 'also': True, 'wrapped': True, 'production': True, 'years': True, 'ago': True, 'sitting': True, 'shelves': True, 'ever': True, 'whatever': True, 'skip': True, 'where': True, 'joblo': True, 'nightmare': True, 'elm': True, 'street': True, '3': True, '7': True, '/': True, '10': True, 'blair': True, 'witch': True, '2': True, 'crow': True, '9': True, 'salvation': True, '4': True, 'stir': True, 'echoes': True, '8': True, 'happy': False, 'bastard': False, 'quick': False, 'damn': False, 'y2k': False, 'bug': False, 'starring': False, 'jamie': False, 'lee': False, 'curtis': False, 'another': False, 'baldwin': False, 'brother': False, 'william': False, 'time': False, 'story': False, 'regarding': False, 'crew': False, 'tugboat': False, 'comes': False, 'across': False, 'deserted': False, 'russian': False, 'tech': False, 'ship': False, 'kick': False, 'power': False, 'within': False, 'gore': False, 'bringing': False, 'few': False, 'action': False, 'sequences': False, 'virus': False, 'empty': False, 'flash': False, 'substance': False, 'why': False, 'was': False, 'middle': False, 'nowhere': False, 'origin': False, 'pink': False, 'flashy': False, 'thing': False, 'hit': False, 'mir': False, 'course': False, 'donald': False, 'sutherland': False, 'stumbling': False, 'around': False, 'drunkenly': False, 'hey': False, 'let': False, 'some': False, 'robots': False, 'acting': False, 'below': False, 'average': False, 'likes': False, 're': False, 'likely': False, 'work': False, 'halloween': False, 'h20': False, 'wasted': False, 'real': False, 'star': False, 'stan': False, 'winston': False, 'robot': False, 'design': False, 'schnazzy': False, 'cgi': False, 'occasional': False, 'shot': False, 'picking': False, 'brain': False, 'if': False, 'body': False, 'parts': False, 'turn': False, 'otherwise': False, 'much': False, 'sunken': False, 'jaded': False, 'viewer': False, 'thankful': False, 'invention': False, 'timex': False, 'indiglo': False, 'based': False, 'late': False, '1960': False, 'television': False, 'show': False, 'name': False, 'mod': False, 'squad': False, 'tells': False, 'tale': False, 'three': False, 'reformed': False, 'criminals': False, 'under': False, 'employ': False, 'police': False, 'undercover': False, 'however': False, 'wrong': False, 'evidence': False, 'gets': False, 'stolen': False, 'immediately': False, 'suspicion': False, 'ads': False, 'cuts': False, 'claire': False, 'dane': False, 'nice': False, 'hair': False, 'cute': False, 'outfits': False, 'car': False, 'chases': False, 'stuff': False, 'blowing': False, 'sounds': False, 'first': False, 'fifteen': False, 'quickly': False, 'becomes': False, 'apparent': False, 'certainly': False, 'slick': False, 'looking': False, 'complete': False, 'costumes': False, 'isn': False, 'enough': False, 'best': False, 'described': False, 'cross': False, 'between': False, 'hour': False, 'long': False, 'cop': False, 'stretched': False, 'span': False, 'single': False, 'clich': False, 'matter': False, 'elements': False, 'recycled': False, 'everything': False, 'already': False, 'seen': False, 'nothing': False, 'spectacular': False, 'sometimes': False, 'bordering': False, 'wooden': False, 'danes': False, 'omar': False, 'epps': False, 'deliver': False, 'their': False, 'lines': False, 'bored': False, 'transfers': False, 'onto': False, 'escape': False, 'relatively': False, 'unscathed': False, 'giovanni': False, 'ribisi': False, 'plays': False, 'resident': False, 'crazy': False, 'man': False, 'ultimately': False, 'being': False, 'worth': False, 'watching': False, 'unfortunately': False, 'save': False, 'convoluted': False, 'apart': False, 'occupying': False, 'screen': False, 'young': False, 'cast': False, 'clothes': False, 'hip': False, 'soundtrack': False, 'appears': False, 'geared': False, 'towards': False, 'teenage': False, 'mindset': False, 'r': False, 'rating': False, 'content': False, 'justify': False, 'juvenile': False, 'older': False, 'information': False, 'literally': False, 'spoon': False, 'hard': False, 'instead': False, 'telling': False, 'dialogue': False, 'poorly': False, 'written': False, 'extremely': False, 'predictable': False, 'progresses': False, 'won': False, 'care': False, 'heroes': False, 'any': False, 'jeopardy': False, 'll': False, 'aren': False, 'basing': False, 'nobody': False, 'remembers': False, 'questionable': False, 'wisdom': False, 'especially': False, 'considers': False, 'target': False, 'fact': False, 'number': False, 'memorable': False, 'can': False, 'counted': False, 'hand': False, 'missing': False, 'finger': False, 'times': False, 'checked': False, 'six': False, 'clear': False, 'indication': False, 'them': False, 'than': False, 'cash': False, 'spending': False, 'dollar': False, 'judging': False, 'rash': False, 'awful': False, 'seeing': False, 'avoid': False, 'at': False, 'costs': False, 'quest': False, 'camelot': False, 'warner': False, 'bros': False, 'feature': False, 'length': False, 'fully': False, 'animated': False, 'steal': False, 'clout': False, 'disney': False, 'cartoon': False, 'empire': False, 'mouse': False, 'reason': False, 'worried': False, 'other': False, 'recent': False, 'challenger': False, 'throne': False, 'last': False, 'fall': False, 'promising': False, 'flawed': False, '20th': False, 'century': False, 'fox': False, 'anastasia': False, 'hercules': False, 'lively': False, 'colorful': False, 'palate': False, 'had': False, 'beat': False, 'hands': False, 'crown': False, '1997': False, 'piece': False, 'animation': False, 'year': False, 'contest': False, 'arrival': False, 'magic': False, 'kingdom': False, 'mediocre': False, '--': False, 'd': False, 'pocahontas': False, 'those': False, 'keeping': False, 'score': False, 'nearly': False, 'dull': False, 'revolves': False, 'adventures': False, 'free': False, 'spirited': False, 'kayley': False, 'voiced': False, 'jessalyn': False, 'gilsig': False, 'early': False, 'daughter': False, 'belated': False, 'knight': False, 'king': False, 'arthur': False, 'round': False, 'table': False, 'dream': False, 'follow': False, 'father': False, 'footsteps': False, 'she': False, 'chance': False, 'evil': False, 'warlord': False, 'ruber': False, 'gary': False, 'oldman': False, 'ex': False, 'gone': False, 'steals': False, 'magical': False, 'sword': False, 'excalibur': False, 'accidentally': False, 'loses': False, 'dangerous': False, 'booby': False, 'trapped': False, 'forest': False, 'help': False, 'hunky': False, 'blind': False, 'timberland': False, 'dweller': False, 'garrett': False, 'carey': False, 'elwes': False, 'headed': False, 'dragon': False, 'eric': False, 'idle': False, 'rickles': False, 'arguing': False, 'itself': False, 'able': False, 'medieval': False, 'sexist': False, 'prove': False, 'fighter': False, 'side': False, 'pure': False, 'showmanship': False, 'essential': False, 'element': False, 'expected': False, 'climb': False, 'high': False, 'ranks': False, 'differentiates': False, 'something': False, 'saturday': False, 'morning': False, 'subpar': False, 'instantly': False, 'forgettable': False, 'songs': False, 'integrated': False, 'computerized': False, 'footage': False, 'compare': False, 'run': False, 'angry': False, 'ogre': False, 'herc': False, 'battle': False, 'hydra': False, 'rest': False, 'case': False, 'stink': False, 'none': False, 'remotely': False, 'interesting': False, 'race': False, 'bland': False, 'end': False, 'tie': False, 'win': False, 'comedy': False, 'shtick': False, 'awfully': False, 'cloying': False, 'least': False, 'signs': False, 'pulse': False, 'fans': False, "-'": False, '90s': False, 'tgif': False, 'will': False, 'thrilled': False, 'jaleel': False, 'urkel': False, 'white': False, 'bronson': False, 'balki': False, 'pinchot': False, 'sharing': False, 'nicely': False, 'realized': False, 'though': False, 'm': False, 'loss': False, 'recall': False, 'specific': False, 'providing': False, 'voice': False, 'talent': False, 'enthusiastic': False, 'paired': False, 'singers': False, 'sound': False, 'musical': False, 'moments': False, 'jane': False, 'seymour': False, 'celine': False, 'dion': False, 'must': False, 'strain': False, 'through': False, 'aside': False, 'children': False, 'probably': False, 'adults': False, 'grievous': False, 'error': False, 'lack': False, 'personality': False, 'learn': False, 'goes': False, 'synopsis': False, 'mentally': False, 'unstable': False, 'undergoing': False, 'psychotherapy': False, 'saves': False, 'boy': False, 'potentially': False, 'fatal': False, 'falls': False, 'love': False, 'mother': False, 'fledgling': False, 'restauranteur': False, 'unsuccessfully': False, 'attempting': False, 'gain': False, 'woman': False, 'favor': False, 'takes': False, 'pictures': False, 'kills': False, 'comments': False, 'stalked': False, 'yet': False, 'seemingly': False, 'endless': False, 'string': False, 'spurned': False, 'psychos': False, 'getting': False, 'revenge': False, 'type': False, 'stable': False, 'category': False, '1990s': False, 'industry': False, 'theatrical': False, 'direct': False, 'proliferation': False, 'may': False, 'due': False, 'typically': False, 'inexpensive': False, 'produce': False, 'special': False, 'effects': False, 'stars': False, 'serve': False, 'vehicles': False, 'nudity': False, 'allowing': False, 'frequent': False, 'night': False, 'cable': False, 'wavers': False, 'slightly': False, 'norm': False, 'respect': False, 'psycho': False, 'never': False, 'affair': False, ';': False, 'contrary': False, 'rejected': False, 'rather': False, 'lover': False, 'wife': False, 'husband': False, 'entry': False, 'doomed': False, 'collect': False, 'dust': False, 'viewed': False, 'midnight': False, 'provide': False, 'suspense': False, 'sets': False, 'interspersed': False, 'opening': False, 'credits': False, 'instance': False, 'serious': False, 'sounding': False, 'narrator': False, 'spouts': False, 'statistics': False, 'stalkers': False, 'ponders': False, 'cause': False, 'stalk': False, 'implicitly': False, 'implied': False, 'men': False, 'shown': False, 'snapshot': False, 'actor': False, 'jay': False, 'underwood': False, 'states': False, 'daryl': False, 'gleason': False, 'stalker': False, 'brooke': False, 'daniels': False, 'meant': False, 'called': False, 'guesswork': False, 'required': False, 'proceeds': False, 'begins': False, 'obvious': False, 'sequence': False, 'contrived': False, 'quite': False, 'brings': False, 'victim': False, 'together': False, 'obsesses': False, 'follows': False, 'tries': False, 'woo': False, 'plans': False, 'become': False, 'desperate': False, 'elaborate': False, 'include': False, 'cliche': False, 'murdered': False, 'pet': False, 'require': False, 'found': False, 'exception': False, 'cat': False, 'shower': False, 'events': False, 'lead': False, 'inevitable': False, 'showdown': False, 'survives': False, 'invariably': False, 'conclusion': False, 'turkey': False, 'uniformly': False, 'adequate': False, 'anything': False, 'home': False, 'either': False, 'turns': False, 'toward': False, 'melodrama': False, 'overdoes': False, 'words': False, 'manages': False, 'creepy': False, 'pass': False, 'demands': False, 'maryam': False, 'abo': False, 'close': False, 'played': False, 'bond': False, 'chick': False, 'living': False, 'daylights': False, 'equally': False, 'title': False, 'ditzy': False, 'strong': False, 'independent': False, 'business': False, 'owner': False, 'needs': False, 'proceed': False, 'example': False, 'suspicions': False, 'ensure': False, 'use': False, 'excuse': False, 'decides': False, 'return': False, 'toolbox': False, 'left': False, 'place': False, 'house': False, 'leave': False, 'door': False, 'answers': False, 'opens': False, 'wanders': False, 'returns': False, 'enters': False, 'our': False, 'heroine': False, 'danger': False, 'somehow': False, 'parked': False, 'front': False, 'right': False, 'oblivious': False, 'presence': False, 'inside': False, 'whole': False, 'episode': False, 'places': False, 'incredible': False, 'suspension': False, 'disbelief': False, 'questions': False, 'validity': False, 'intelligence': False, 'receives': False, 'highly': False, 'derivative': False, 'somewhat': False, 'boring': False, 'cannot': False, 'watched': False, 'rated': False, 'mostly': False, 'several': False, 'murder': False, 'brief': False, 'strip': False, 'bar': False, 'offensive': False, 'many': False, 'thrillers': False, 'mood': False, 'stake': False, 'else': False, 'capsule': False, '2176': False, 'planet': False, 'mars': False, 'taking': False, 'custody': False, 'accused': False, 'murderer': False, 'face': False, 'menace': False, 'lot': False, 'fighting': False, 'john': False, 'carpenter': False, 'reprises': False, 'ideas': False, 'previous': False, 'assault': False, 'precinct': False, '13': False, 'homage': False, 'himself': False, '0': False, '+': False, 'believes': False, 'fight': False, 'horrible': False, 'writer': False, 'supposedly': False, 'expert': False, 'mistake': False, 'ghosts': False, 'drawn': False, 'humans': False, 'surprisingly': False, 'low': False, 'powered': False, 'alien': False, 'addition': False, 'anybody': False, 'made': False, 'grounds': False, 'sue': False, 'chock': False, 'full': False, 'pieces': False, 'prince': False, 'darkness': False, 'surprising': False, 'managed': False, 'fit': False, 'admittedly': False, 'novel': False, 'science': False, 'fiction': False, 'experience': False, 'terraformed': False, 'walk': False, 'surface': False, 'without': False, 'breathing': False, 'gear': False, 'budget': False, 'mentioned': False, 'gravity': False, 'increased': False, 'earth': False, 'easier': False, 'society': False, 'changed': False, 'advanced': False, 'culture': False, 'women': False, 'positions': False, 'control': False, 'view': False, 'stagnated': False, 'female': False, 'beyond': False, 'minor': False, 'technological': False, 'advances': False, 'less': False, '175': False, 'expect': False, 'change': False, 'ten': False, 'basic': False, 'common': False, 'except': False, 'yes': False, 'replaced': False, 'tacky': False, 'rundown': False, 'martian': False, 'mining': False, 'colony': False, 'having': False, 'criminal': False, 'napolean': False, 'wilson': False, 'desolation': False, 'williams': False, 'facing': False, 'hoodlums': False, 'automatic': False, 'weapons': False, 'nature': False, 'behave': False, 'manner': False, 'essentially': False, 'human': False, 'savages': False, 'lapse': False, 'imagination': False, 'told': False, 'flashback': False, 'entirely': False, 'filmed': False, 'almost': False, 'tones': False, 'red': False, 'yellow': False, 'black': False, 'powerful': False, 'scene': False, 'train': False, 'rushing': False, 'heavy': False, 'sadly': False, 'buildup': False, 'terror': False, 'creates': False, 'looks': False, 'fugitive': False, 'wannabes': False, 'rock': False, 'band': False, 'kiss': False, 'building': False, 'bunch': False, 'sudden': False, 'jump': False, 'sucker': False, 'thinking': False, 'scary': False, 'happening': False, 'standard': False, 'haunted': False, 'shock': False, 'great': False, 'newer': False, 'unimpressive': False, 'digital': False, 'decapitations': False, 'fights': False, 'short': False, 'stretch': False, 'release': False, 'mission': False, 'panned': False, 'reviewers': False, 'better': False, 'rate': False, 'scale': False, 'following': False, 'showed': False, 'liked': False, 'moderately': False, 'classic': False, 'comment': False, 'twice': False, 'ask': False, 'yourself': False, '8mm': False, 'eight': False, 'millimeter': False, 'wholesome': False, 'surveillance': False, 'sight': False, 'values': False, 'becoming': False, 'enmeshed': False, 'seedy': False, 'sleazy': False, 'underworld': False, 'hardcore': False, 'pornography': False, 'bubbling': False, 'beneath': False, 'town': False, 'americana': False, 'sordid': False, 'sick': False, 'depraved': False, 'necessarily': False, 'stop': False, 'order': False, 'satisfy': False, 'twisted': False, 'desires': False, 'position': False, 'influence': False, 'kinds': False, 'demented': False, 'talking': False, 'snuff': False, 'supposed': False, 'documentaries': False, 'victims': False, 'brutalized': False, 'killed': False, 'camera': False, 'joel': False, 'schumacher': False, 'credit': False, 'batman': False, 'robin': False, 'kill': False, 'forever': False, 'client': False, 'thirds': False, 'unwind': False, 'fairly': False, 'conventional': False, 'persons': False, 'drama': False, 'albeit': False, 'particularly': False, 'unsavory': False, 'core': False, 'threatening': False, 'along': False, 'explodes': False, 'violence': False, 'think': False, 'finally': False, 'tags': False, 'ridiculous': False, 'self': False, 'righteous': False, 'finale': False, 'drags': False, 'unpleasant': False, 'trust': False, 'waste': False, 'hours': False, 'nicolas': False, 'snake': False, 'eyes': False, 'cage': False, 'private': False, 'investigator': False, 'tom': False, 'welles': False, 'hired': False, 'wealthy': False, 'philadelphia': False, 'widow': False, 'determine': False, 'whether': False, 'reel': False, 'safe': False, 'documents': False, 'girl': False, 'assignment': False, 'factly': False, 'puzzle': False, 'neatly': False, 'specialized': False, 'skills': False, 'training': False, 'easy': False, 'cops': False, 'toilet': False, 'tanks': False, 'clues': False, 'deeper': False, 'digs': False, 'investigation': False, 'obsessed': False, 'george': False, 'c': False, 'scott': False, 'paul': False, 'schrader': False, 'occasionally': False, 'flickering': False, 'whirs': False, 'sprockets': False, 'winding': False, 'projector': False, 'reminding': False, 'task': False, 'hints': False, 'toll': False, 'lovely': False, 'catherine': False, 'keener': False, 'frustrated': False, 'cleveland': False, 'ugly': False, 'split': False, 'level': False, 'harrisburg': False, 'pa': False, 'condemn': False, 'condone': False, 'subject': False, 'exploits': False, 'irony': False, 'seven': False, 'scribe': False, 'andrew': False, 'kevin': False, 'walker': False, 'vision': False, 'lane': False, 'limited': False, 'hollywood': False, 'product': False, 'snippets': False, 'covering': False, 'later': False, 'joaquin': False, 'phoenix': False, 'far': False, 'adult': False, 'bookstore': False, 'flunky': False, 'max': False, 'california': False, 'cover': False, 'horrid': False, 'screened': False, 'familiar': False, 'revelation': False, 'sexual': False, 'deviants': False, 'indeed': False, 'monsters': False, 'everyday': False, 'neither': False, 'super': False, 'nor': False, 'shocking': False, 'banality': False, 'exactly': False, 'felt': False, 'weren': False, 'nine': False, 'laughs': False, 'months': False, 'terrible': False, 'mr': False, 'hugh': False, 'grant': False, 'huge': False, 'dork': False, 'oral': False, 'sex': False, 'prostitution': False, 'referring': False, 'bugs': False, 'annoying': False, 'adam': False, 'sandler': False, 'jim': False, 'carrey': False, 'eye': False, 'flutters': False, 'nervous': False, 'smiles': False, 'slapstick': False, 'fistfight': False, 'delivery': False, 'room': False, 'culminating': False, 'joan': False, 'cusack': False, 'lap': False, 'paid': False, '$': False, '60': False, 'included': False, 'obscene': False, 'double': False, 'entendres': False, 'obstetrician': False, 'pregnant': False, 'pussy': False, 'size': False, 'hairs': False, 'coat': False, 'nonetheless': False, 'exchange': False, 'cookie': False, 'cutter': False, 'originality': False, 'humor': False, 'successful': False, 'child': False, 'psychiatrist': False, 'psychologist': False, 'scriptwriters': False, 'could': False, 'inject': False, 'unfunny': False, 'kid': False, 'dad': False, 'asshole': False, 'eyelashes': False, 'offers': False, 'smile': False, 'responds': False, 'english': False, 'accent': False, 'attitude': False, 'possibly': False, '_huge_': False, 'beside': False, 'includes': False, 'needlessly': False, 'stupid': False, 'jokes': False, 'olds': False, 'everyone': False, 'shakes': False, 'anyway': False, 'finds': False, 'usual': False, 'reaction': False, 'fluttered': False, 'paves': False, 'possible': False, 'pregnancy': False, 'birth': False, 'gag': False, 'book': False, 'friend': False, 'arnold': False, 'provides': False, 'cacophonous': False, 'funny': False, 'beats': False, 'costumed': False, 'arnie': False, 'dinosaur': False, 'draw': False, 'parallels': False, 'toy': False, 'store': False, 'jeff': False, 'goldblum': False, 'hid': False, 'dreadful': False, 'hideaway': False, 'artist': False, 'fear': False, 'simultaneous': False, 'longing': False, 'commitment': False, 'doctor': False, 'recently': False, 'switch': False, 'veterinary': False, 'medicine': False, 'obstetrics': False, 'joke': False, 'old': False, 'foreign': False, 'guy': False, 'mispronounces': False, 'stereotype': False, 'say': False, 'yakov': False, 'smirnov': False, 'favorite': False, 'vodka': False, 'hence': False, 'take': False, 'volvo': False, 'nasty': False, 'unamusing': False, 'heads': False, 'simultaneously': False, 'groan': False, 'failure': False, 'loud': False, 'failed': False, 'uninspired': False, 'lunacy': False, 'sunset': False, 'boulevard': False, 'arrest': False, 'please': False, 'caught': False, 'pants': False, 'bring': False, 'theaters': False, 'faces': False, '90': False, 'forced': False, 'unauthentic': False, 'anyone': False, 'q': False, '80': False, 'sorry': False, 'money': False, 'unfulfilled': False, 'desire': False, 'spend': False, 'bucks': False, 'call': False, 'road': False, 'trip': False, 'walking': False, 'wounded': False, 'stellan': False, 'skarsg': False, 'rd': False, 'convincingly': False, 'zombified': False, 'drunken': False, 'loser': False, 'difficult': False, 'smelly': False, 'boozed': False, 'reliable': False, 'swedish': False, 'adds': False, 'depth': False, 'significance': False, 'plodding': False, 'aberdeen': False, 'sentimental': False, 'painfully': False, 'mundane': False, 'european': False, 'playwright': False, 'august': False, 'strindberg': False, 'built': False, 'career': False, 'families': False, 'relationships': False, 'paralyzed': False, 'secrets': False, 'unable': False, 'express': False, 'longings': False, 'accurate': False, 'reflection': False, 'strives': False, 'focusing': False, 'pairing': False, 'alcoholic': False, 'tomas': False, 'alienated': False, 'openly': False, 'hostile': False, 'yuppie': False, 'kaisa': False, 'lena': False, 'headey': False, 'gossip': False, 'haven': False, 'spoken': False, 'wouldn': False, 'norway': False, 'scotland': False, 'automobile': False, 'charlotte': False, 'rampling': False, 'sand': False, 'rotting': False, 'hospital': False, 'bed': False, 'cancer': False, 'soap': False, 'opera': False, 'twist': False, 'days': False, 'live': False, 'blitzed': False, 'step': False, 'foot': False, 'plane': False, 'hits': False, 'open': False, 'loathing': False, 'each': False, 'periodic': False, 'stops': False, 'puke': False, 'dashboard': False, 'whenever': False, 'muttering': False, 'rotten': False, 'turned': False, 'sloshed': False, 'viewpoint': False, 'recognizes': False, 'apple': False, 'hasn': False, 'fallen': False, 'tree': False, 'nosebleeds': False, 'snorting': False, 'coke': False, 'sabotages': False, 'personal': False, 'indifference': False, 'restrain': False, 'vindictive': False, 'temper': False, 'ain': False, 'pair': False, 'true': False, 'notes': False, 'unspoken': False, 'familial': False, 'empathy': False, 'note': False, 'repetitively': False, 'bitchy': False, 'screenwriters': False, 'kristin': False, 'amundsen': False, 'hans': False, 'petter': False, 'moland': False, 'fabricate': False, 'series': False, 'contrivances': False, 'propel': False, 'forward': False, 'roving': False, 'hooligans': False, 'drunks': False, 'nosy': False, 'flat': False, 'tires': False, 'figure': False, 'schematic': False, 'convenient': False, 'narrative': False, 'reach': False, 'unveil': False, 'dark': False, 'past': False, 'simplistic': False, 'devices': False, 'trivialize': False, 'conflict': False, 'mainstays': False, 'wannabe': False, 'exists': False, 'purely': False, 'sake': False, 'weak': False, 'unimaginative': False, 'casting': False, 'thwarts': False, 'pivotal': False, 'role': False, 'were': False, 'stronger': False, 'actress': False, 'perhaps': False, 'coast': False, 'performances': False, 'moody': False, 'haunting': False, 'cinematography': False, 'rendering': False, 'pastoral': False, 'ghost': False, 'reference': False, 'certain': False, 'superior': False, 'indie': False, 'intentional': False, 'busy': False, 'using': False, 'furrowed': False, 'brow': False, 'convey': False, 'twitch': False, 'insouciance': False, 'paying': False, 'attention': False, 'maybe': False, 'doing': False, 'reveal': False, 'worthwhile': False, 'earlier': False, 'released': False, '2001': False, 'jonathan': False, 'nossiter': False, 'captivating': False, 'wonders': False, 'disturbed': False, 'parental': False, 'figures': False, 'bound': False, 'ceremonial': False, 'wedlock': False, 'differences': False, 'presented': False, 'significant': False, 'luminous': False, 'diva': False, 'preening': False, 'static': False, 'solid': False, 'performance': False, 'pathetic': False, 'drunk': False, 'emote': False, 'besides': False, 'catatonic': False, 'sorrow': False, 'genuine': False, 'ferocity': False, 'sexually': False, 'charged': False, 'frisson': False, 'during': False, 'understated': False, 'confrontations': False, 'suggest': False, 'gray': False, 'zone': False, 'complications': False, 'accompany': False, 'torn': False, 'romance': False, 'stifled': False, 'curiosity': False, 'thoroughly': False, 'explores': False, 'neurotic': False, 'territory': False, 'delving': False, 'americanization': False, 'greece': False, 'mysticism': False, 'illusion': False, 'deflect': False, 'pain': False, 'overloaded': False, 'willing': False, 'come': False, 'traditional': False, 'ambitious': False, 'sleepwalk': False, 'rhythms': False, 'timing': False, 'driven': False, 'stories': False, 'complexities': False, 'depressing': False, 'answer': False, 'lawrence': False, 'kasdan': False, 'trite': False, 'useful': False, 'grand': False, 'canyon': False, 'steve': False, 'martin': False, 'mogul': False, 'pronounces': False, 'riddles': False, 'answered': False, 'advice': False, 'heart': False, 'french': False, 'sees': False, 'parents': False, 'tim': False, 'roth': False, 'oops': False, 'vows': False, 'taught': False, 'musketeer': False, 'dude': False, 'used': False, 'fourteen': False, 'arrgh': False, 'swish': False, 'zzzzzzz': False, 'original': False, 'lacks': False, 'energy': False, 'next': False, 'hmmmm': False, 'justin': False, 'chambers': False, 'basically': False, 'uncharismatic': False, 'version': False, 'chris': False, 'o': False, 'donnell': False, 'range': False, 'mena': False, 'suvari': False, 'thora': False, 'birch': False, 'dungeons': False, 'dragons': False, 'miscast': False, 'deliveries': False, 'piss': False, 'poor': False, 'ms': False, 'fault': False, 'definitely': False, 'higher': False, 'semi': False, 'saving': False, 'grace': False, 'wise': False, 'irrepressible': False, 'once': False, 'thousand': False, 'god': False, 'beg': False, 'agent': False, 'marketplace': False, 'modern': False, 'day': False, 'roles': False, 'romantic': False, 'gunk': False, 'alright': False, 'yeah': False, 'yikes': False, 'notches': False, 'fellas': False, 'blares': False, 'ear': False, 'accentuate': False, 'annoy': False, 'important': False, 'behind': False, 'recognize': False, 'epic': False, 'fluffy': False, 'rehashed': False, 'cake': False, 'created': False, 'shrewd': False, 'advantage': False, 'kung': False, 'fu': False, 'phenomenon': False, 'test': False, 'dudes': False, 'keep': False, 'reading': False, 'editing': False, 'shoddy': False, 'banal': False, 'stilted': False, 'plentiful': False, 'top': False, 'horse': False, 'carriage': False, 'stand': False, 'opponent': False, 'scampering': False, 'cut': False, 'mouseketeer': False, 'rope': False, 'tower': False, 'jumping': False, 'chords': False, 'hanging': False, 'says': False, '14': False, 'shirt': False, 'strayed': False, 'championing': False, 'fun': False, 'stretches': False, 'atrocious': False, 'lake': False, 'reminded': False, 'school': False, 'cringe': False, 'musketeers': False, 'fat': False, 'raison': False, 'etre': False, 'numbers': False, 'hoping': False, 'packed': False, 'stuntwork': False, 'promoted': False, 'trailer': False, 'major': False, 'swashbuckling': False, 'beginning': False, 'finishes': False, 'juggling': False, 'ladders': False, 'ladder': False, 'definite': False, 'keeper': False, 'regurgitated': False, 'crap': False, 'tell': False, 'deneuve': False, 'placed': False, 'hullo': False, 'barely': False, 'ugh': False, 'small': False, 'annoyed': False, 'trash': False, 'gang': False, 'vow': False, 'stay': False, 'thank': False, 'outlaws': False, '5': False, 'crouching': False, 'tiger': False, 'hidden': False, 'matrix': False, 'replacement': False, 'killers': False, '6': False, 'romeo': False, 'die': False, 'shanghai': False, 'noon': False, 'remembered': False, 'dr': False, 'hannibal': False, 'lecter': False, 'michael': False, 'mann': False, 'forensics': False, 'thriller': False, 'manhunter': False, 'scottish': False, 'brian': False, 'cox': False, 'works': False, 'usually': False, 'schlock': False, 'halfway': False, 'goodnight': False, 'meaty': False, 'substantial': False, 'brilliant': False, 'check': False, 'dogged': False, 'inspector': False, 'opposite': False, 'frances': False, 'mcdormand': False, 'ken': False, 'loach': False, 'agenda': False, 'harrigan': False, 'disturbing': False, 'l': False, 'e': False, '47': False, 'picked': False, 'sundance': False, 'distributors': False, 'scared': False, 'budge': False, 'dares': False, 'speak': False, 'expresses': False, 'seeking': False, 'adolescents': False, 'pad': False, 'bothered': False, 'members': False, 'presentation': False, 'oddly': False, 'empathetic': False, 'light': False, 'tempered': False, 'robust': False, 'listens': False, 'opposed': False, 'friends': False, 'wire': False, 'act': False, 'confused': False, 'lives': False, 'pay': False, 'courtship': False, 'charming': False, 'temptations': False, 'grown': False, 'stands': False, 'island': False, 'expressway': False, 'slices': False, 'malls': False, 'class': False, 'homes': False, 'suburbia': False, 'filmmaker': False, 'cuesta': False, 'uses': False, 'transparent': False, 'metaphor': False, '15': False, 'protagonist': False, 'howie': False, 'franklin': False, 'dano': False, 'reveals': False, 'morbid': False, 'preoccupation': False, 'death': False, 'citing': False, 'deaths': False, 'alan': False, 'j': False, 'pakula': False, 'songwriter': False, 'harry': False, 'chapin': False, 'exit': False, '52': False, 'fascinated': False, 'feelings': False, 'projected': False, 'bright': False, 'move': False, 'force': False, 'complex': False, 'molesters': False, 'beast': False, 'ashamed': False, 'worked': False, 'ill': False, 'advised': False, 'foray': False, 'unnecessary': False, 'padding': False, 'miserable': False, 'bruce': False, 'altman': False, 'seat': False, 'collar': False, 'crime': False, 'degenerate': False, 'youngsters': False, 'kicks': False, 'robbing': False, 'houses': False, 'homoerotic': False, 'shenanigans': False, 'ass': False, 'terrio': False, 'billy': False, 'kay': False, 'handsome': False, 'artful': False, 'dodger': False, 'add': False, 'themes': False, 'suburban': False, 'ennui': False, 'needed': False, 'awkward': False, 'subplots': False, 'concurrently': False, 'relationship': False, 'evenly': False, 'paced': False, 'exceptionally': False, 'acted': False, 'sporting': False, 'baseball': False, 'cap': False, 'faded': False, 'marine': False, 'tattoo': False, 'bluff': False, 'bluster': False, 'quiet': False, 'glance': False, 'withdrawn': False, 'whose': False, 'dramatic': False, 'choices': False, 'broad': False, 'calling': False, 'haley': False, 'restraint': False, 'admirable': False, 'screenplay': False, 'material': False, 'reads': False, 'walt': False, 'whitman': False, 'poem': False, 'moment': False, 'precious': False, 'lingers': False, 'ecstatic': False, 'hearing': False, 'glenn': False, 'gould': False, 'performing': False, 'bach': False, 'goldberg': False, 'variations': False, 'involving': False, 'walter': False, 'masterson': False, 'jealous': False, 'newbie': False, 'thread': False, 'predictably': False, 'leads': False, 'observational': False, 'portrait': False, 'alienation': False, 'royally': False, 'screwed': False, 'terry': False, 'zwigoff': False, 'superb': False, 'confidence': False, 'ambivalent': False, 'typical': False, 'cinema': False, 'wrap': False, 'bullet': False, 'sparing': False, 'writers': False, 'philosophical': False, 'regard': False, 'countless': False, 'share': False, 'blockbuster': False, 'solved': False, 'obstacle': False, 'removed': False, 'often': False, 'extend': False, 'question': False, 'striving': False, 'realism': False, 'destroy': False, 'janeane': False, 'garofalo': False, 'couple': False, 'truth': False, 'cats': False, 'dogs': False, 'excruciating': False, 'matchmaker': False, 'books': False, 'plods': False, 'predestined': False, 'surprises': False, 'jumps': False, 'popular': False, 'political': False, 'satire': False, 'bandwagon': False, 'campaign': False, 'aide': False, 'massacusetts': False, 'senator': False, 'sanders': False, 'reelection': False, 'denis': False, 'leary': False, 'stereotypical': False, 'strategist': False, 'ethics': False, 'scandal': False, 'plagued': False, 'play': False, 'irish': False, 'roots': False, 'boston': False, 'roman': False, 'catholic': False, 'democrat': False, 'contingent': False, 'kennedy': False, 'family': False, 'orders': False, 'ireland': False, 'relatives': False, 'exploit': False, 'soon': False, 'learns': False, 'said': False, 'done': False, 'mantra': False, 'tiny': False, 'misses': False, 'bus': False, 'hotel': False, 'ends': False, 'smallest': False, 'trashiest': False, 'dog': False, 'luggage': False, 'roger': False, 'ebert': False, 'calls': False, 'meet': False, 'happens': False, 'unconventional': False, 'cinematic': False, 'walks': False, 'bathroom': False, 'nude': False, 'sean': False, 'david': False, 'hara': False, 'bathtub': False, 'points': False, 'guessing': False, 'water': False, 'hates': False, 'instant': False, 'saw': False, 'irishman': False, 'hate': False, 'awhile': False, 'succumb': False, 'charms': False, 'happily': False, 'superficial': False, 'detail': False, 'throw': False, 'turmoil': False, 'reconcile': False, 'tune': False, 'annual': False, 'matchmaking': False, 'festival': False, 'lonely': False, 'county': False, 'future': False, 'bliss': False, 'milo': False, 'shea': False, 'snyder': False, 'pops': False, 'onscreen': False, 'spew': False, 'souls': False, 'assured': False, 'match': False, 'utter': False, 'predictability': False, 'message': False, 'respectable': False, 'person': False, 'comedic': False, 'distinction': False, 'sell': False, 'script': False, 'excited': False, 'stays': False, 'stateside': False, 'yelling': False, 'phone': False, 'undoes': False, 'microphone': False, 'speech': False, 'known': False, 'flying': False, 'hong': False, 'kong': False, 'style': False, 'filmmaking': False, 'classics': False, 'nod': False, 'asia': False, 'france': False, 'lukewarm': False, 'dumas': False, 'asian': False, 'stunt': False, 'coordinator': False, 'xing': False, 'xiong': False, 'prior': False, 'attempts': False, 'choreography': False, 'laughable': False, 'van': False, 'damme': False, 'vehicle': False, 'team': False, 'dennis': False, 'rodman': False, 'simon': False, 'sez': False, 'thrown': False, 'air': False, 'result': False, 'tepid': False, 'adventure': False, 'rip': False, 'stinks': False, 'indiana': False, 'jones': False, 'simple': False, 'grandmother': False, 'adapted': False, 'artagnan': False, 'vengeful': False, 'son': False, 'slain': False, 'travels': False, 'paris': False, 'join': False, 'royal': False, 'meets': False, 'cunning': False, 'cardinal': False, 'richelieu': False, 'stephen': False, 'rea': False, 'overthrow': False, 'associate': False, 'febre': False, 'killer': False, 'disbanded': False, 'rounds': False, 'aramis': False, 'nick': False, 'moran': False, 'athos': False, 'jan': False, 'gregor': False, 'kremp': False, 'porthos': False, 'steven': False, 'spiers': False, 'wrongfully': False, 'imprisoned': False, 'leader': False, 'treville': False, 'prison': False, 'frisky': False, 'interest': False, 'chambermaid': False, 'francesca': False, 'footsy': False, 'coo': False, 'hunts': False, 'queen': False, 'captured': False, 'menancing': False, 'forcing': False, 'regroup': False, 'leading': False, 'charge': False, 'peter': False, 'hyams': False, 'wanted': False, 'blend': False, 'eastern': False, 'western': False, 'styles': False, 'disaster': False, 'reality': False, 'ones': False, 'jet': False, 'li': False, 'risk': False, 'ironically': False, 'swordplay': False, 'spread': False, 'carry': False, 'bulk': False, '30': False, 'minute': False, 'picture': False, 'weighs': False, 'monotonous': False, 'gene': False, 'quintano': False, 'prosaic': False, 'wedding': False, 'planner': False, 'mousy': False, 'artangnan': False, 'hyam': False, 'candles': False, 'torches': False, 'grime': False, 'filth': False, '17th': False, 'noted': False, 'standout': False, 'mortal': False, 'kombat': False, 'annihilation': False, 'reviewed': False, 'multiple': False, 'levels': False, 'rampant': False, 'usage': False, 'randian': False, 'subtext': False, 'pervades': False, 'occasionaly': False, 'ironic': False, 'depreciating': False, 'remark': False, 'tosses': False, 'clearly': False, 'marxist': False, 'imagery': False, 'kidding': False, 'seriousness': False, 'fair': False, '*': False, 'necessary': False, 'viewpoints': False, 'watcher': False, 'unfamiliar': False, 'marginally': False, 'fan': False, 'games': False, '1995': False, 'concerned': False, 'martial': False, 'arts': False, 'tournament': False, 'decide': False, 'fate': False, 'billion': False, 'inhabitants': False, 'mortals': False, 'theory': False, 'prevented': False, 'emperor': False, 'shao': False, 'khan': False, 'arriving': False, 'ready': False, 'assumed': False, 'stance': False, 'extraordinarily': False, 'myself': False, 'game': False, 'enjoyed': False, 'directors': False, 'knew': False, 'limitations': False, 'try': False, 'overachieve': False, 'accompanying': False, 'intersperesed': False, 'distracting': False, 'non': False, 'intrusive': False, 'bits': False, 'fluff': False, 'passing': False, 'smashing': False, 'success': False, 'box': False, 'office': False, 'picks': False, 'precisely': False, 'introductory': False, 'exposition': False, 'anyways': False, 'hell': False, 'silly': False, 'rule': False, 'winning': False, 'thereafter': False, 'approximately': False, '85': False, 'alternates': False, 'general': False, 'impression': False, 'producers': False, 'thought': False, 'formula': False, 'volumes': False, 'truly': False, 'sandra': False, 'hess': False, 'sonya': False, 'blade': False, 'execrable': False, 'convince': False, 'loved': False, 'johnny': False, 'greased': False, 'worst': False, 'mis': False, 'james': False, 'remar': False, 'raiden': False, 'thunder': False, 'christopher': False, 'lambert': False, 'japanese': False, 'revered': False, 'chinese': False, 'mystics': False, 'against': False, 'lister': False, 'jr': False, 'president': False, 'u': False, 'fifth': False, 'utility': False, 'totally': False, 'luxury': False, 'amused': False, 'awareness': False, 'introduced': False, 'meaningless': False, 'sidetracks': False, 'including': False, 'muddled': False, 'liu': False, 'kang': False, 'shou': False, 'seeks': False, 'nightwolf': False, 'litefoot': False, 'mystical': False, 'hallucination': False, 'jade': False, 'irina': False, 'pantaeva': False, 'reasons': False, 'unless': False, 'critiques': False, 'apply': False, 'worse': False, 'bridgette': False, 'convincing': False, 'looked': False, 'mimicing': False, 'movements': False, 'choreographer': False, 'knows': False, 'puts': False, 'believable': False, 'jax': False, 'earthquake': False, 'animality': False, 'bonus': False, 'similar': False, 'moves': False, 'mistakenly': False, 'hang': False, 'lamest': False, 'involved': False, 'mud': False, 'wrestling': False, 'lame': False, 'politically': False, 'incorrect': False, 'noticed': False, 'remarked': False, 'upon': False, 'emporer': False, 'perform': False, 'animalities': False, 'motaro': False, 'sheeva': False, 'lifelike': False, 'goro': False, 'enjoy': False, 'femme': False, 'la': False, 'nikita': False, 'backdraft': False, 'sliver': False, 'cindy': False, 'crawford': False, 'anne': False, 'parillaud': False, 'conspire': False, 'shattered': False, 'image': False, 'hooey': False, 'stallone': False, 'stone': False, 'specialist': False, 'poses': False, 'recurring': False, 'assassin': False, 'honeymooning': False, 'jamaica': False, 'believe': False, 'runs': False, 'painful': False, 'pedestrian': False, 'siouxsie': False, 'sioux': False, 'wig': False, 'emotionless': False, 'leather': False, 'clothing': False, 'seattle': False, 'moping': False, 'karen': False, 'endlessly': False, 'complicated': False, 'plots': False, 'helps': False, 'crisp': False, 'modicum': False, 'shakespearean': False, 'begin': False, 'saddled': False, 'leaden': False, 'zero': False, 'breaking': False, 'cardboard': False, 'confines': False, 'insist': False, 'couldn': False, 'huh': False, 'wonderful': False, 'interchange': False, 'charm': False, 'faster': False, 'learned': False, 'cereal': False, 'crybaby': False, 'imagines': False, 'stranger': False, 'sends': False, 'flowers': False, 'chromium': False, 'tough': False, 'nails': False, 'crack': False, 'killing': False, 'machine': False, 'shoots': False, 'mirrors': False, 'stock': False, 'interested': False, 'nest': False, 'egg': False, 'pave': False, 'paradise': False, 'put': False, 'parking': False, 'graham': False, 'greene': False, 'barbet': False, 'schroeder': False, 'reversal': False, 'fortune': False, 'co': False, 'produced': False, 'agonizingly': False, 'b': False, 'york': False, 'vampires': False, 'latest': False, 'opus': False, 'bent': False, 'outing': False, 'aptly': False, 'titled': False, 'suppose': False, 'went': False, 'prefixed': False, 'possessive': False, 'unashamed': False, 'punctuated': False, 'above': False, 'storyline': False, 'borders': False, 'idiotic': False, 'chaotic': False, 'dormant': False, 'martians': False, 'swirling': False, 'gases': False, 'awakened': False, 'meddling': False, 'possess': False, 'hapless': False, 'colonists': False, 'testy': False, 'marilyn': False, 'manson': False, 'lookalikes': False, 'pooh': False, 'bah': False, 'counsel': False, 'official': False, 'melanie': False, 'ballard': False, 'natasha': False, 'henstridge': False, 'sub': False, 'species': False, 'returnee': False, 'officer': False, 'incarcerated': False, 'felon': False, 'second': False, 'blonde': False, 'pulled': False, 'tightly': False, 'awkwardly': False, 'ponytail': False, 'ice': False, 'cube': False, 'appropriately': False, 'named': False, 'pam': False, 'grier': False, 'briefly': False, 'whom': False, 'wonder': False, 'host': False, 'extras': False, 'therefore': False, 'bird': False, 'shots': False, 'sprawling': False, 'metropolis': False, 'reddish': False, 'state': False, 'art': False, 'trademark': False, 'finding': False, 'department': False, 'lock': False, 'laughing': False, 'barrel': False, 'fare': False, 'dingy': False, 'interiors': False, 'cluttered': False, 'exteriors': False, 'inane': False, 'lots': False, 'scarred': False, 'crazed': False, 'aliens': False, 'weaponry': False, 'warfare': False, 'warning': False, 'spontaneously': False, 'stupidly': False, 'villains': False, 'border': False, 'conflicts': False, 'shootouts': False, 'minus': False, 'hissing': False, 'plissken': False, 'miss': False, 'dubbed': False, 'minimalist': False, 'soundtracks': False, 'graduated': False, 'effective': False, 'scoring': False, 'highlighting': False, 'screeching': False, 'guitar': False, 'fortunately': False, 'drowns': False, 'er': False, 'audible': False, 'priceless': False, 'proven': False, 'infertile': False, 'breeding': False, 'ground': False, 'stillborn': False, 'val': False, 'kilmer': False, 'disappointing': False, 'weekend': False, 'overshadowed': False, 'sequels': False, 'among': False, 'pie': False, 'rush': False, 'absent': False, 'references': False, 'set': False, 'perth': False, 'amboys': False, 'closest': False, 'neighbor': False, 'slap': False, 'upside': False, '1': False, 'keeps': False, 'miraculously': False, 'pretend': False, 'means': False, 'intelligent': False, 'grade': False, 'sci': False, 'fi': False, 'singularly': False, 'luck': False, 'starting': False, 'alicia': False, 'silverstone': False, 'beautiful': False, 'creatures': False, 'green': False, 'critic': False, 'large': False, 'choosing': False, 'strikes': False, 'crush': False, 'slow': False, 'moving': False, 'horrific': False, 'adaptation': False, 'clueless': False, 'mailed': False, 'saying': False, 'theater': False, 'expecting': False, 'preview': False, 'crazymadinlove': False, 'whiny': False, 'unlikable': False, 'wasn': False, 'yelled': False, 'f': False, '$&#': False, 'laugh': False, 'agreement': False, 'walked': False, 'babysitter': False, 'inner': False, 'compulsion': False, 'understand': False, 'rent': False, 'regret': False, 'paragraph': False, 'competition': False, 'criticizing': False, 'thin': False, 'shred': False, 'slower': False, 'glacier': False, 'writing': False, 'appeal': False, 'whatsoever': False, 'pointlessly': False, 'concluded': False, 'violent': False, 'plus': False, 'equals': False, 'spends': False, 'twenty': False, 'bubble': False, 'bath': False, 'joined': False, 'four': False, 'features': False, 'settle': False, 'friday': False, 'cocktail': False, 'automatically': False, 'nights': False, 'trods': False, 'discover': False, 'silent': False, 'object': False, 'male': False, 'fantasies': False, 'thinks': False, 'recapture': False, 'youth': False, 'boyfriend': False, 'lets': False, 'wild': False, 'spying': False, 'outside': False, 'prepubescent': False, 'keyhole': False, 'aged': False, 'counterpart': False, 'asked': False, '200': False, 'pound': False, 'silk': False, 'teddy': False, 'fanatasies': False, 'realm': False, 'pg': False, 'imagine': False, 'cinemax': False, 'staple': False, 'absolutely': False, 'pointed': False, 'classify': False, 'mix': False, 'various': False, 'encounters': False, 'third': False, 'space': False, 'odyssey': False, 'apollo': False, 'contact': False, 'hope': False, 'melange': False, 'considering': False, 'disastrous': False, 'results': False, 'sucks': False, 'rescue': False, 'astronauts': False, 'sent': False, '2020': False, 'unknown': False, 'aviators': False, 'visit': False, 'underwhelming': False, 'describe': False, 'uneven': False, 'promise': False, 'buzz': False, 'neutral': False, 'cherry': False, 'colored': False, 'nerdies': False, 'techie': False}
Then we can do this for all of our documents, saving the feature existence booleans and their respective positive or negative categories by doing:
15. BAG OF WORDS
Bag of Words (BoW) is a model used in natural language processing. One aim of BoW is to categorize documents. The idea is to analyse and classify different “bags of words” (corpus). And by matching the different categories, we identify which “bag” a certain block of text (test data) comes from.
The Bag of Words model learns a vocabulary from all of the documents, then models each document by counting the number of times each word appears. For example, consider the following two sentences: Sentence 1: “The cat sat on the hat” Sentence 2: “The dog ate the cat and the hat” From these two sentences, our vocabulary is as follows: { the, cat, sat, on, hat, dog, ate, and } To get our bags of words, we count the number of times each word occurs in each sentence. In Sentence 1, “the” appears twice, and “cat”, “sat”, “on”, and “hat” each appear once, so the feature vector for Sentence 1 is: { the, cat, sat, on, hat, dog, ate, and } Sentence 1: { 2, 1, 1, 1, 1, 0, 0, 0 } Similarly, the features for Sentence 2 are: { 3, 1, 0, 0, 1, 1, 1, 1}
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'All my cats in a row',
'When my cat sits down, she looks like a Furby toy!',
'The cat from outer space',
'Sunshine loves to sit like this for some reason.'
]
vectorizer = CountVectorizer()
print( vectorizer.fit_transform(corpus).todense() )
print( vectorizer.vocabulary_ )[[1 0 1 0 0 0 0 1 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0]
[0 1 0 1 0 0 1 0 1 1 0 1 0 0 0 1 0 1 0 0 0 0 0 0 1 1]
[0 1 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 1 0 0 0 0]
[0 0 0 0 1 0 0 0 1 0 1 0 0 1 0 0 1 0 1 0 1 0 1 1 0 0]]
{'all': 0, 'my': 11, 'cats': 2, 'in': 7, 'row': 14, 'when': 25, 'cat': 1, 'sits': 17, 'down': 3, 'she': 15, 'looks': 9, 'like': 8, 'furby': 6, 'toy': 24, 'the': 21, 'from': 5, 'outer': 12, 'space': 19, 'sunshine': 20, 'loves': 10, 'to': 23, 'sit': 16, 'this': 22, 'for': 4, 'some': 18, 'reason': 13}
16. So what is TF-IDF?
TF-IDF stands for term frequency-inverse document frequency, and the tf-idf weight is a weight often used in information retrieval and text mining. This weight is a statistical measure used to evaluate how important a word is to a document in a collection or corpus. The importance increases proportionally to the number of times a word appears in the document but is offset by the frequency of the word in the corpus. Variations of the tf-idf weighting scheme are often used by search engines as a central tool in scoring and ranking a document’s relevance given a user query.
One of the simplest ranking functions is computed by summing the tf-idf for each query term; many more sophisticated ranking functions are variants of this simple model.
Typically, the tf-idf weight is composed by two terms: the first computes the normalized Term Frequency (TF), aka. the number of times a word appears in a document, divided by the total number of words in that document; the second term is the Inverse Document Frequency (IDF), computed as the logarithm of the number of the documents in the corpus divided by the number of documents where the specific term appears.
TF: Term Frequency, which measures how frequently a term occurs in a document. Since every document is different in length, it is possible that a term would appear much more times in long documents than shorter ones. Thus, the term frequency is often divided by the document length (aka. the total number of terms in the document) as a way of normalization:
TF(t) = (Number of times term t appears in a document) / (Total number of terms in the document).
IDF: Inverse Document Frequency, which measures how important a term is. While computing TF, all terms are considered equally important. However it is known that certain terms, such as “is”, “of”, and “that”, may appear a lot of times but have little importance. Thus we need to weigh down the frequent terms while scale up the rare ones, by computing the following:
IDF(t) = log_e(Total number of documents / Number of documents with term t in it).
See below for a simple example.
Example:
Consider a document containing 100 words wherein the word cat appears 3 times.
The term frequency (i.e., tf) for cat is then (3 / 100) = 0.03. Now, assume we have 10 million documents and the word cat appears in one thousand of these. Then, the inverse document frequency (i.e., idf) is calculated as log(10,000,000 / 1,000) = 4. Thus, the Tf-idf weight is the product of these quantities: 0.03 * 4 = 0.12.
Term Frequency (TF) Matrix :
This is the most obvious technique to find out the relevance of a word in a document. The more frequent a word is, the more relevance the word holds in the context. Here is a frequency count of a set of words in the 5 books :
TF = 1 + log (TF) if TF > 00 if TF = 0
Let’s do the same calculation here :
Now to find the relevance of document in the query, you just need to sum up the values of words in the query.
Document 1 : 1.7 + 3.1 + 2.8 + 1 = 8.6
Document 2 :2.3 + 3.0 + 0 + 2 = 7.3
Document 3 : 2.5 + 3.0 + 0 + 2 = 7.5
Document 4 : 2.6 + 3.0 + 0 + 2.3 = 7.9
Document 5 : 2.3 + 3.0 + 0 + 2.5 = 7.8
Result shows, Document 1 will be more relevant to display for the query, but we still make a concrete conclusion . Since, document 4 and 5 are not far away from Document 1. They might turn out to be relevant too. This is because of the stopwords which elevates all the scores with similar magnitude.
Inverse Document Frequency Matrix(IDF) :
IDF is another parameter which helps us find out the relevance of words. It is based on the principle that less frequent words are generally more informative.
IDF = log (N/DF)
where N represents the number of documents and DF represents the number of documents in which we see the occurrence of this word.

We now can clearly see that the words like “The” “for” etc. are not really relevant as they occur in almost all the document. Whereas, words like honest, Analytics Big-Data are really niche words which should be kept in the analysis.
TF-IDF Matrix :
As we now know the relevance of words (IDF) and the occurrence of words in the documents (TF), we now can multiply the two. Then, find the subject of the document and thereafter the similarity of query with the document.
Now it clearly comes out that document 1 is most relevant to the query.
17. Word Embedding (text vectors)
Word embedding is the modern way of representing words as vectors. The aim of word embedding is to redefine the high dimensional word features into low dimensional feature vectors by preserving the contextual similarity in the corpus. They are widely used in deep learning models such as Convolutional Neural Networks and Recurrent Neural Networks.
Word2Vec is a popular model to create word embedding of a text. This models takes a text corpus as input and produces the word vectors as output.
Word2Vec model is composed of preprocessing module, a shallow neural network model called Continuous Bag of Words and another shallow neural network model called skip-gram. This model is widely used for all other nlp problems. It first constructs a vocabulary from the training corpus and then learns word embedding representations. Following code using gensim package prepares the word embedding as the vectors.
18. Text Matching / Similarity
One of the important areas of NLP is the matching of text objects to find similarities. Important applications of text matching includes automatic spelling correction, data de-duplication and genome analysis etc.
A number of text matching techniques are available depending upon the requirement. This section describes the important techniques in detail.
- Levenshtein Distance – The Levenshtein distance between two strings is defined as the minimum number of edits needed to transform one string into the other, with the allowable edit operations being insertion, deletion, or substitution of a single character. Following is the implementation for efficient memory computations.
def levenshtein(s1,s2):
if len(s1) > len(s2):
s1,s2 = s2,s1
distances = range(len(s1) + 1)
for index2,char2 in enumerate(s2):
newDistances = [index2+1]
for index1,char1 in enumerate(s1):
if char1 == char2:
newDistances.append(distances[index1])
else:
newDistances.append(1 + min((distances[index1], distances[index1+1], newDistances[-1])))
distances = newDistances
return distances[-1]
print(levenshtein("analyze","analyse"))1
References:
[https://pythonprogramming.net/tokenizing-words-sentences-nltk-tutorial/]