
Introduction
If you are reading this blog, you will probably be familiar with machine learning or will be interested in learning the same. Machine learning is a subfield of artificial intelligence, where it makes the systems to learn from data and make them capable of taking decisions with minimal human intervention. Now generally, we use the word “model” to indicate this intelligent system. Now, suppose we have a model which is designed to perform a particular task. This task can be anything like, for example, classifying the emails as not spam and spam, or an image classification problem. Now, with this model, we need to know two important things
- Is the model good enough for performing the task
- Is the performance of model degrading with new data
Now, these points are really important when it comes to model development. These factors will determine how good the model is and how the model can be improved. Now, how do we know if the model is good or not?
There comes the role of performance metrics. Let us see what it is.
Performance Metrics For Classification
So we need some way to tell how well our model is doing. But how can we use a single metric to do that?
Accuracy
One way is to check how many times the model made correct decisions and how many mistakes it made. This idea will take us to the most simple performance metric – Accuracy. Accuracy can be defined as the percentage of correct decisions made by the model. This makes perfect sense right? The more is the value of accuracy, the better will be the model. But this can be tricky sometimes. Let us see an example.
Consider a cancer prediction case study. Given the details of a person, we need to predict whether they have cancer or not. Assume, we have a model trained for this task. Now, there are four scenarios that can happen.
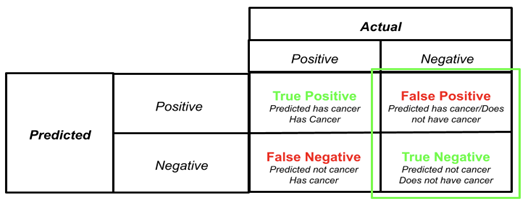
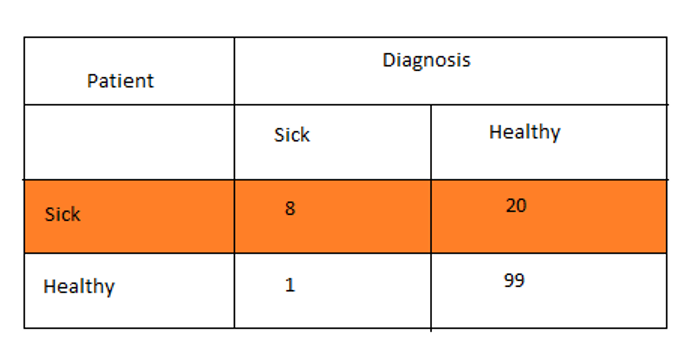
Now from this figure, the number of True positives and true negatives indicate how well the model is. Let us assign some values also.
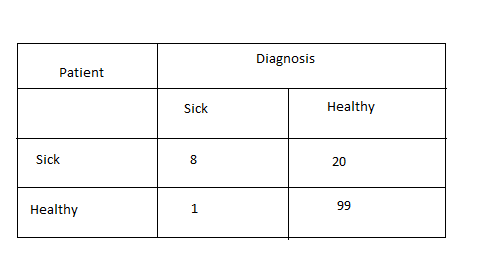
Now we can see the number of false positives from the model is very high. Here out of 28 cancer patients, 20 patients are falsely identified as healthy. Now this is a serious issue. We cannot afford a single mistake of not identifying an actual cancer patient. Considering this, we can say this model is performing poorly. Now, let us check the accuracy of the model. The number of correct predictions from the model is 107 (99+8) and the number of mistakes is 21 (20+1). Now the accuracy will be
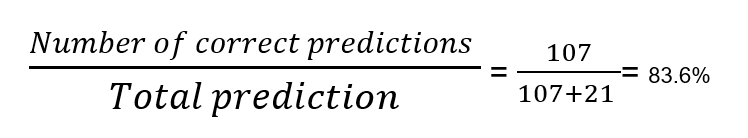
Even though the model is performing terribly, we can see that the accuracy of the model is very high. If we have considered accuracy only, we might think this model as a good one as would have used this model for actual scenarios. From this example, we understood that a simple metric like accuracy cannot be used as a performance evaluation metric in all cases
Precision and Recall
We saw in our previous example, that accuracy metric can sometimes be misleading. Now let us try to derive some more appropriate error metrics. From the confusion matrix shown above, we can come up with two different metrics – Precision and Recall
Precision
Precision indicates how precise or correct our predictions are. If we connect with our previous example, we can define precision in this way. Out of the patients who were diagnosed as sick, how many patients are actually sick. Now, if the value of precision is more, then our diagnosis is more accurate. We can also calculate the precision on healthy people identification as well. Let us try to calculate the precision of our previous model. The figure below is the same confusion matrix which we saw earlier.
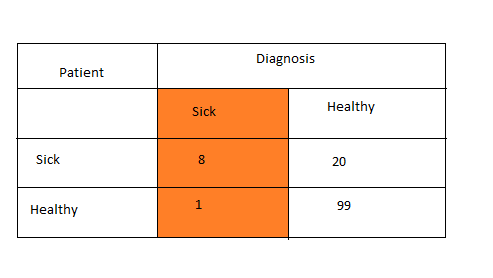
Now, you can see out of 9 people, who were diagnosed as sick, 8 people were actually sick, but one person was healthy. So, here this one person is not actually sick, but since the model identified him as sick, he has to do all the further medical check ups, which is annoying. Here only one person is misclassified, which is good. But if this misclassification is more, that will give us very bad results. Now let us calculate the precision of this model.
Precision is the percentage of correct predictions. Here precision for diagnosis= sick is
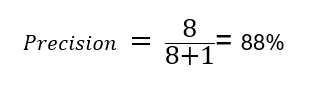
Similarly we can calculate the precision for diagnosis = Healthy. Here we calculate, out of the total patients who were diagnosed as healthy, how many were actually healthy. From the confusion matrix we can see that 99 people were actually healthy, and 20 people were actually sick but detected as healthy. That means our model is terrible, right?
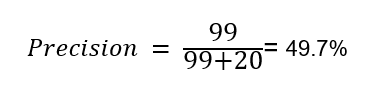
So it is clear that the model is doing a poor job in detecting the sick patients. Now let us see what recall means
Recall
In some use cases, recall is a very important metric. Recall will tell us, out of the patients who were actually sick, how many patients were identified to be sick. So we can say that recall is a very important metric in the medical domain. Because in the medical domain, less precision will only identify some healthy person as sick. That can be annoying, but it is not very serious. But imagine a case where recall is less. Less recall means, we are not able to identify the actual sick patients and we diagnosed them as healthy. That will be terrible. So in this scenario, we need to check if the model has a high recall or not.
Now here, we can see out of 28 sick patients, only 8 were detected as sick, and the majority(20) of the patients are diagnosed as healthy, which is terrible. Now let us see the recall of this model.
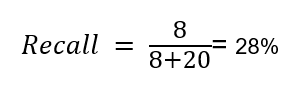
We see that selection of a performance metric is purely based on data and the domain. In the same example use case, we saw the accuracy of the model as 83% and the recall of the same model as 28%. Obviously considering the data and the domain, we came to know that accuracy is not a good metric in this case. We should be smart enough by selecting the most appropriate metric while evaluating the model, otherwise the evaluation results will mislead us.
Now that we know about precision and recall, how do we know when to use precision and when to use recall?

Yes. What if we can combine precision and recall and make a single metric. That would be great, right? Let us see.
F1 Score
Now how can we combine two metrics to form a single metric. The most simple way will be to take the average of these metrics, right? Now let us see how that will look like. Let us consider the same medical model.We are considering the class Diagnosed=Sick.
For the model, Precision = 88% and Recall = 28%
Now the average of these scores will be
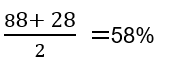
Well, this may give us a feeling that the model is not bad, it gives an average score close to 60%. But we can also see how bad the recall is. Considering that, we can say that the average score is not considering the terrible scenario of the model. So we cannot take average as a single metric. Now what?
Let me introduce a new term – Harmonic mean. The Harmonic mean is like average, but it is different. The Harmonic mean between two numbers can be written as:
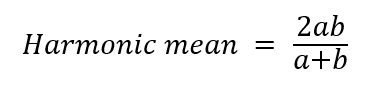
Harmonic mean will be less than the arithmetic mean, or the average and it will be closer towards the smallest number. So if either precision or recall is low, then the harmonic mean will also be low. Now let us try to calculate the harmonic mean between the precision and recall
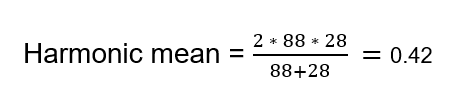
The harmonic mean between the precision and recall will have a value ranging from 0 to1. The higher the mean, the better the model. Here, we can see here that the harmonic mean of the model is very less and this is a clear indicator that our model is not good.
The harmonic mean between the precision and recall is called as F1 Score. F1 score is a very popular and widely used metric in many cases, as it tries to capture the worst case scenarios also.
Performance Metrics For Regression
The metrics like accuracy, precision, recall and F1 score are only applicable only if the problem is classification. Consider a scenario where you were told to develop a machine learning model to predict the prices of houses. The type of problem where the output label is a real number instead of a class value (for example: sick or not sick), is called a regression problem. Now, if the output label is a real number the metrics like accuracy, precision, recall, etc. does not make any sense. There we have to use some other metrics.
RMSE
RMSE or root mean squared error is the most popular and widely used metric in regression problems. Now RMSE calculation will take an assumption that the errors are normally distributed and they are unbiased. Given below is the equation for RMSE
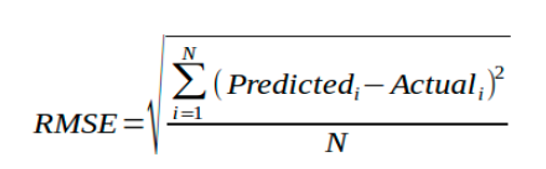
Many Machine learning algorithms use RMSE, because it is faster and easier to compute. Great. Then we can always use RMSE no matter what?

Here, we can see that errors are squared and due to which RMSE will not be in the same scale as the errors. RMSE will also penalize large errors, which is not good in some cases. RMSE is also highly affected by outliers.
MAE
MAE or Mean Absolute Error is another metric which we can use for regression problems.
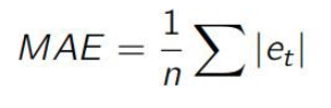
Here e represents the error between the prediction and actual value. MAE will measure the average magnitude of errors, without considering the direction or sign of that error. The MAE is a linear score which means that all the individual differences are weighted equally in the average. MAE clearly has the advantage of not penalizing the large errors, which is really helpful in some cases. But one distinct disadvantage of using MAE is that it uses the absolute value which is undesirable in many mathematical calculations.
Similar to the classification metrics, the use of regression metrics also depends on the data and domain.
Conclusions
In this blog I tried to cover some most commonly used error metrics in machine learning. Please note that I had only covered a few of the most commonly used performance metrics. There are many other metrics also which I haven’t covered here. You can explore that also.
For any queries or suggestions, please feel to contact me through LinkedIn
You can also check out my projects on Github